Egnyte’s Guide to Sensitive Data and How to Keep It Safe
Sensitive information is any data that, if compromised, could cause serious harm, such as physical injury, financial loss, identity theft, or reputational damage, to individuals or organizations. Examples: Financial account details, health records, login credentials, and government‑issued IDs.
Sensitive data requires heightened protection to prevent unauthorized access and misuse. Compromised sensitive information can expose businesses to operational, reputational, and legal risks under sensitive data protection regulations. This guide outlines how to identify, locate, and protect sensitive data effectively.
Let’s jump in and learn:
- Why Is Sensitive Data Important?
- Types of Sensitive Data
- Sensitive Data That Hackers or Malicious Insiders Would Look For
- Sensitive Data vs. Personal Data
- Determining and Measuring Data Sensitivity
- Data Classification and Data Privacy
- What Happens If Sensitive Data Is Leaked: Risk Factors
- Navigating the Landscape of Data Privacy Regulations With Egnyte
- Case Study:
- Conclusion
- Frequently Asked Questions
Why Is Sensitive Data Important?
Sensitive data, such as personal identifiers, financial details, health records, and biometric or genetic information, is critical to protect because its exposure can have far-reaching consequences. If compromised, this data can lead to identity theft, fraud, discrimination, or even damage to personal dignity and autonomy.
With so many services, banking, healthcare, and education now digital, a single breach can lead to fraud, identity theft, or significant financial losses, such as supply chain risks or third-party vendor exposure.
Regulations like HIPAA and FERPA establish guidelines for handling sensitive information, thereby ensuring public trust. As threats from cybercriminals increase, proactive protection of sensitive data is essential.
Types of Sensitive Data
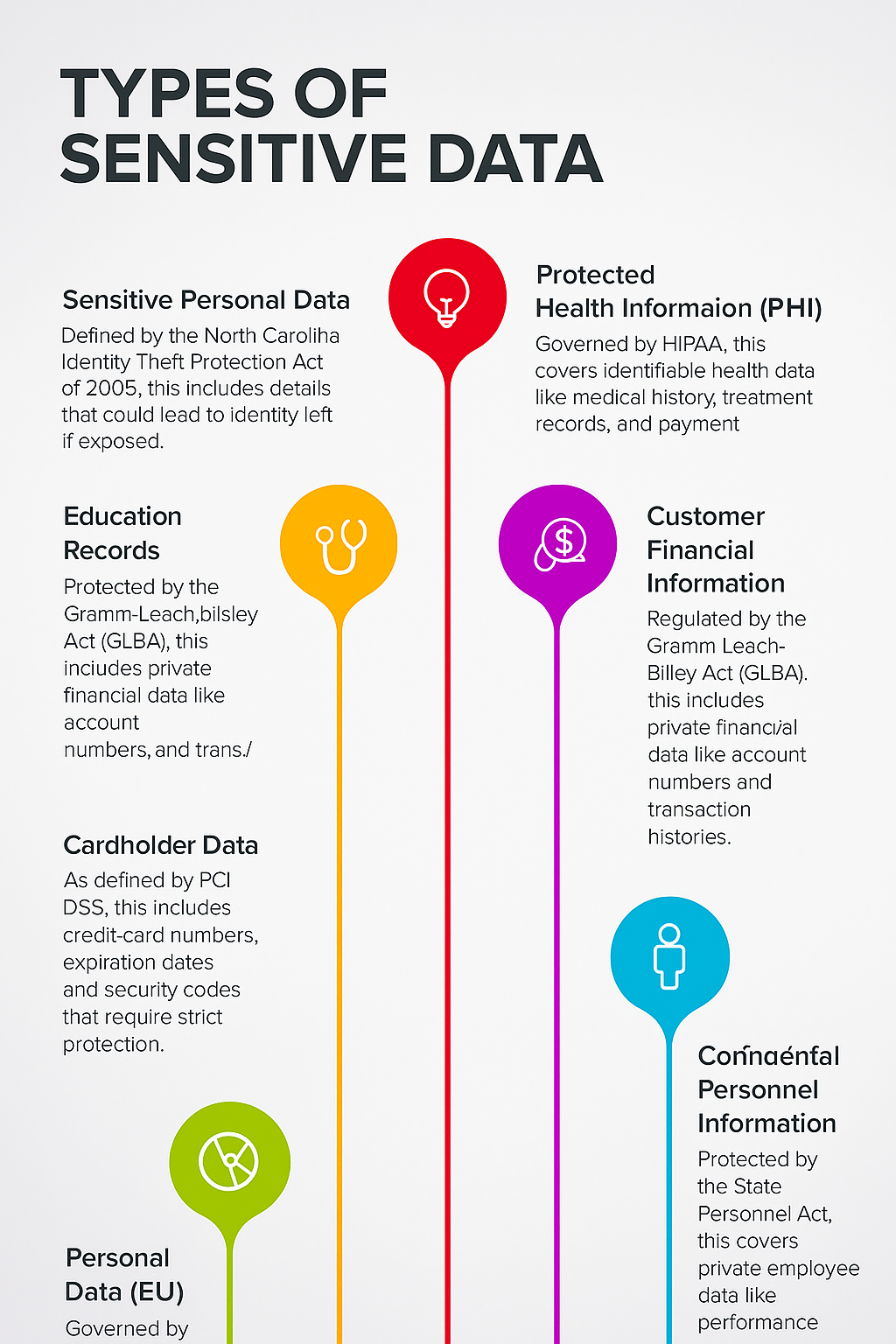
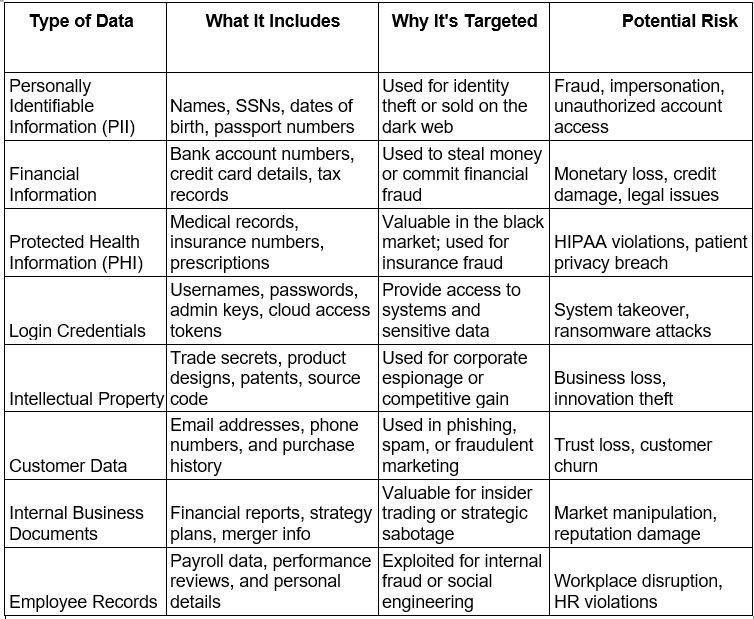
Sensitive Data That Hackers or Malicious Insiders Would Look For
Sensitive Data vs. Personal Data
Personal data refers to any information that can identify an individual, such as name, email address, or phone number. It is often shared in daily interactions and may not always require strict legal protection.
Sensitive data is a subset of personal data that, if exposed, could cause significant harm to an individual or organisation. Examples include health records, financial account details, login credentials, and government‑issued IDs. Sensitive data is usually governed by strict regulatory requirements and demands stronger protection measures.
Determining and Measuring Data Sensitivity
Organizations assess data sensitivity using frameworks like the CIA Triad: Confidentiality, Integrity, and Availability.
- Confidentiality: How damaging would unauthorised access be?
- Integrity: How critical is the accuracy and trustworthiness of the data?
- Availability: How essential is continuous access for operations?
To add structure and granularity, organizations often pair the CIA Triad with formal classification frameworks:
- NIST SP 800-60 provides a methodical approach for mapping data types and systems to security categories based on impact levels (low, moderate, and high).
- ISO/IEC 27001 establishes an Information Security Management System (ISMS) that uses the CIA principles within a management framework for ongoing risk assessment and control implementation.
- ISO/IEC 27701 extends this with privacy-specific requirements, enabling organizations to manage personally identifiable information through a Privacy Information Management System (PIMS) layered onto their ISMS.
Data is considered more sensitive when it has a high potential to cause harm if confidentiality, integrity, or availability is compromised.
Data Classification and Data Privacy
Data classification is the foundation of effective governance. For executives, it provides a risk‑based map of the information landscape, enabling investment decisions that align protection with business value.
Common tiers:
- Public – No material harm if disclosed.
- Internal – Internal‑only; minimal regulatory risk.
- Confidential – Potential to harm operations or reputation.
- Restricted – Critical to business continuity and regulatory compliance.
Robust classification accelerates compliance with frameworks such as GDPR, HIPAA, and CCPA, while ensuring scarce security resources protect the highest‑value assets.
What Happens If Sensitive Data Is Leaked: Risk Factors
A sensitive data breach is a business‑critical event with far‑reaching consequences:
- Regulatory Exposure – Violations of GDPR, HIPAA, CCPA, or other privacy laws can trigger multi‑million‑dollar fines, consent decrees, and heightened regulatory scrutiny.
- Financial Loss – Incident response, legal defence, customer compensation, and remediation costs can erode profitability and affect quarterly earnings.
- Reputational Damage – Loss of customer confidence, negative press cycles, and diminished brand equity can impact market share long after the breach.
- Operational Disruption – Downtime from containment, investigation, and system restoration can disrupt revenue streams and strategic projects.
- Litigation Risk – Class‑action lawsuits and shareholder actions can extend the financial and reputational damage for years.
In a high‑stakes breach scenario, speed of detection, decisiveness in response, and transparency in communication can significantly reduce both immediate and long‑term damage.
Navigating the Landscape of Data Privacy Regulations With Egnyte
Even high‑performing teams face challenges managing sprawling, unstructured content. Without centralized oversight, sensitive files can be duplicated, misplaced, or left unprotected, creating compliance risks and operational inefficiencies.
Egnyte addresses these challenges with a unified governance platform that combines clarity, control, and enterprise‑grade security. It delivers secure access, version control, and consistent policy enforcement across distributed teams.
The platform supports the entire data lifecycle, automating compliance from creation to archival, which is critical for regulated industries where protection, traceability, and audit readiness are non-negotiable
Case Study:
Wintrust Unifies Content Governance Amid Rapid Growth
Wintrust, a leading financial services provider operating 16 community banks and multiple non‑bank businesses, faced mounting governance challenges. Unstructured data was scattered across systems, making retention, discovery, access control, and classification inconsistent. These gaps slowed collaboration, created departmental friction, and made compliance enforcement difficult.
Wintrust replaced ShareFile and legacy file servers with Egnyte as its central, cloud‑based content management platform. Egnyte’s governance framework allowed each department to tailor policies without disrupting daily workflows. Key capabilities included:
- Intuitive interface for quick adoption
- Secure & Govern tools for access, permissions, and retention
- Clear separation of shared vs. personal directories for visibility
- Advanced search and content discovery to reduce time spent locating files
- Automated sensitive data detection and ransomware protection
- Real‑time visibility into enterprise file sharing and user activity
As a result, the Wintrust team achieves 20-30 minutes in file-related task savings per user daily, translating to about 2,500 hours saved monthly across the company. Also, it increased storage as it grew by $20 billion in assets and 2,000 employees.
Read the full story here
Conclusion
In an era where data privacy regulations are tightening and breaches carry unprecedented financial and reputational costs, compliance is a board‑level priority. The ability to identify, govern, and protect sensitive information is now directly linked to business resilience and market trust.
Egnyte empowers organisations to move beyond reactive compliance toward proactive governance. By unifying content management, automating regulatory alignment, and delivering real‑time visibility, it enables leadership teams to minimise risk while unlocking operational efficiency.
For enterprises navigating complex privacy landscapes, Egnyte transforms compliance from a regulatory obligation into a strategic differentiator, helping you safeguard data, build customer confidence, and scale securely into the future.
Frequently Asked Questions
Q. What is the difference between sensitive and non-sensitive data?
Sensitive data is information that, if exposed, could harm an individual or organization through financial loss, identity theft, reputational damage, operational disruption, or legal consequences. Examples include passwords, Social Security numbers, bank account details, medical records, and proprietary business information. Loss of this data can lead to fraud, competitive disadvantage, or compliance penalties. It therefore requires strong safeguards such as encryption, secure storage, and restricted access.
Non-sensitive data, on its own, does not present a serious risk if disclosed, such as a public job title or company name. However, it can become sensitive when combined with other information through data aggregation, which is why it still warrants careful handling.
Q. Why is sensitive data important?
Many people still ask, what is sensitive data, and why does it need special protection? It is important because it directly impacts people’s privacy, safety, and identity. If leaked, it can cause fraud, emotional harm, or legal problems. z
Q. Which data is considered sensitive?
Anything that could be misused or cause harm is considered sensitive. It includes: Login details, Financial records, Health information, Government IDs, Trade secrets, and Biometric data.
Q. What is another name for sensitive data?
Other common names include: Confidential data, Private data, Protected information, Restricted data, and Sensitive information.
Q. How does sensitive information relate to data storage?
Sensitive information should never be stored in plain, readable form. Industry standards and regulations, such as PCI DSS for payment card data, HIPAA for health records, and GDPR for personal data, require robust measures to prevent unauthorized access and ensure compliance.
Egnyte has experts ready to answer your questions. For more than a decade, Egnyte has helped more than 22,000+ customers with millions of users worldwide.
Additional Resources

Secure Sensitive Gmail Data with Egnyte
Egnyte integrates with Gmail to quickly locate and protect sensitive information, ensuring compliance and data security.

Managing Sensitive Data in Microsoft Repositories
Egnyte helps identify and control sensitive information across Microsoft repositories, ensuring security and compliance.

What Is Data Security?
Protect data from breaches and unauthorized access with encryption and strict access controls.