Data Backup: Definition, Options, and Technologies
A data backup program, or routinely making additional copies of data, plays a key role in security programs and disaster recovery (also referred to as contingency planning). It can also be used to restore the original data to earlier instances.

Data backup protects data from accidental loss and corruption, hardware failure, power failure, and natural disasters, as well as unauthorized access and cyberattacks. Though referred to as data backup, the process can include applications and system data to facilitate full restoration after an incident.
Let’s jump in and learn:
What Is Data Backup?
Data backup is a process of duplicating data to allow retrieval and restoration to systems if the original data is needed. Information is copied to another system, where it is stored. Best practices dictate that data backup storage includes an offsite component.
Data backup frequency presents a challenge for most organizations. Scheduling should be based on the type of data and its importance to the organization. Other considerations for data backup frequency include:
- Resource availability to manage data backup functions
- Requirements as specified by stakeholders and management
- Recovery Time Objective (RTO) and Recovery Point Objective (RPO) SLAs (service level agreements)
Determining best practices for data backup depends on the organization and its internal and external (e.g., SLAs, compliance) requirements. Commonly followed best practices include the following:
- Understand existing backup policies
- Create a data backup policy, if one is not in place, that includes:
- Who is responsible for data backup?
- Where is the data backup stored?
- What are the data backup access policies?
- How often should data backup be done?
- How is data moved during a backup (e.g., encrypted)?
- How long should data be retained?
- Automate data backup
- Back up metadata assigned to data
- Locate the backup data in several locations, one of which is offsite (e.g., the 3-2-1 data backup strategy, which is explained in further detail below)
- Verify backups to ensure validity by performing spot checks to:
- Confirm that there are no errors in opening files
- Ensure that the file dates and sizes are identical to the original copies
- Perform a checksum to verify that the original and backup files are identical
- Consider digitizing physical documents
What Data Should Be Included in a Backup?
Any data that cannot be easily recreated or replaced should be included in data backup as a rule of thumb. The list of information in a data backup varies, but a few common examples are:
- Business administration documents
- Communications
- Credit card transactions/receipts
- Customer databases
- Financial data and documents
- Personnel records
- Property and tax records
- Software used by employees
- Frequently updated files
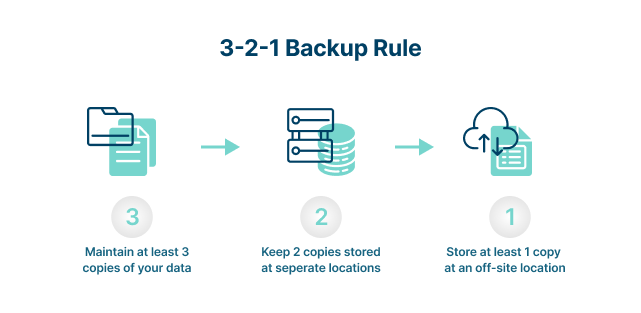
What Is the 3-2-1 Data Backup Strategy?
A 3-2-1 data backup strategy provides a structure and process for ensuring data resilience under almost any circumstance. Designed to take into account a number of worst-case scenarios, the data backup strategy ensures that at least one copy of data will be available to use for recovery and operations restoration.
The 3-2-1 data backup strategy is brilliant in its simplicity. The way it works is this:
- Three
Always have at least three distinct copies of the data—one is the production set, and the other two are backups. - Two
At least two copies of the production data should be kept on secure storage devices that are physically independent of each other. A commonly used tactic is to have one backup stored on a network-attached device or a file server and another stored on removable media or another server. - One
At least one copy of the two backups should be stored at a separate location from the production data and the other backup. A common recommendation is to store the backup data in the cloud at two geographically separated locations.
Data Backup and a Disaster Recovery Plan
Backup and disaster recovery (BDR) combines data backup and disaster recovery to ensure an organization’s resilience and operations continuity. While data backup and disaster recovery are different, most organizations utilize them together.
The reason for this is simple; data backup can exist without disaster recovery, but not the other way around. Without a data backup, there is virtually nothing to recover.
Having data backup and disaster recovery systems in place is an important first step, but documenting what to do in the event of a crisis is vital. A well-thought-out plan that is rigorously and regularly tested will allow an organization to resume operations quickly in the event of a disaster. A data backup and disaster recovery plan should consider the following:
- What data needs to be recovered?
- What is the ranking of data set recovery priorities?
- Are there dependencies that could affect the recovery?
- Do any post-restoration steps need to be taken?
The primary objectives of a data backup and recovery plan are to:
- Limit the extent of damage, including disruption of normal operations
- Minimize the economic impact of the disruption
- Establish contingencies for alternative operational infrastructure and access to data
- Train personnel to be effective participants in an organization’s response to a disaster
- Ensure a fast and smooth restoration of services
What Are RPO and RTO?
Both RTO (recovery time objective) and RPO (recovery point objective) involve measurements of time after a service disruption—100% uptime (RTO) and no lost data (RPO). However, while RTO focuses on returning hardware and software to full availability, including data recovery, RPO focuses on the amount of time between the loss of data and the preceding data backup. For both RTO and RPO, the acceptable amount of time is driven by the priority given to applications and data.
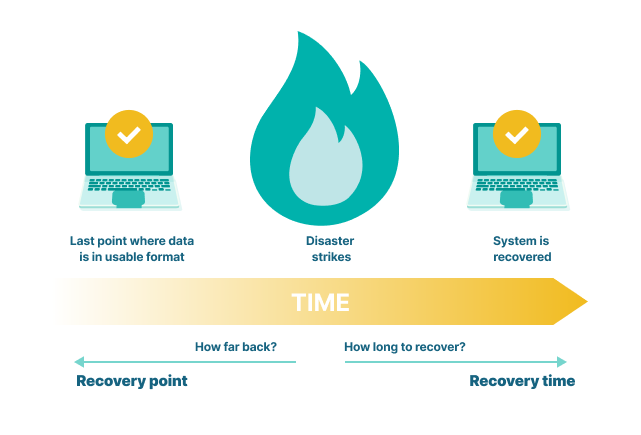
RPO
The acceptable amount of lost data following a failure event drives RPO and data backup strategies. The technology to achieve different RPO varies, but a few rough numbers give an idea of what is involved:
- 8-24 hours of downtime:
Requires external storage data backups of the production environment, with the last available data backup serving as a restoration point - Up to 4 hours of downtime:
Requires ongoing snapshots of the production environment - Near-zero downtime:
Requires data backup and storage solutions that mirror data, usually cloud-based with replication in multiple geographic locations
To calculate RPO, organizations must weigh the cost of data backup solutions against the cost of lost data. For instance, a high-traffic e-commerce site would have a far different RPO and data backup strategy than a local bakery. Factors to consider when calculating RPO are:
- Cost of lost data and operations
- Cost of data backup and recovery solutions
RTO
RTO dictates how quickly systems, data, and applications need to be back online after a service disruption or disaster. It is often defined as the maximum downtime an organization can sustain and still maintain business continuity.
For some organizations, an RTO is minutes. For others, it can be hours (i.e., time from service disruption notice to restoration of service). For outsourced IT services, the RTO is defined with the service level agreement (SLA).
A few factors to consider when calculating RTO are:
- Cost per minute or hour of outage
- Importance and priority of individual systems (Note that the frequency of use does not dictate the importance. For instance, an infrequently used system could be just as critical as one that is used all the time)
- Steps required to mitigate or recover from a service disruption or disaster
- Cost/benefit equation for data backup and other recovery solutions
Data Backup Options
When thinking about data backup, the type and the location of backup should be considered. In addition, how backups are run should be taken into account. For example, hot or dynamic backup backs up data while allowing users to access it.
This type of data backup avoids downtime and enables data backup to be run at any time, but if users make changes during the backup, the changes will not be included. Conversely, cold backups, sometimes known as offline backups, lock files during backups to ensure that no files can be changed during the backup process. Depending on requirements, one or more of these options could be the best choice.
Options for Types of Data Backup
Differential backup
This type of data backup stores a cumulative backup of changes made since the last full backup, or the differences since the last full backup. The downside to differential backups is that the file is not an exact copy of a file, but rather a file created based on the original file and any subsequent modifications to that file.
Full-disk backup
Full-disk backup captures a copy of an entire data set. However, though it is considered the most reliable data backup method, it is time-consuming and media-consuming (e.g., disks, tapes), which can result in increased costs.
Incremental backup
Only the data that has changed since the last full backup is included in incremental backups. While this saves time in the short term, a full restore takes longer when an incremental backup is used.
Incremental-forever backup
This captures the full data set and then supplements it with incremental backups of changed blocks from that point forward.
Mirror backup
Used mostly for smaller organizations or individuals, mirror backup provides a real-time duplicate of the source being backed up. When a file in the source is deleted, that file is eventually also deleted in the mirror backup.
Many online backup services offer a mirror backup with a 30-day delete. This means that if a user deletes a file, that file is kept on the storage server for at least 30 days before it is eventually deleted.
Synthetic full backup
Creates a backup that is based on the original full backup and data, including changes, from incremental backups.
Options for the Locations of Data Backup
- Local backup
Places data behind a network firewall, typically stored on external hard disk drives (HDDs) or magnetic tape systems that are usually housed in an on-premises data center. The data is transmitted over a secure high-bandwidth network connection or corporate intranet. - Cloud or remote data backup
Transmits data backup to a remote location, such as an organization’s secondary data center, leased colocation facility, a cloud service provider, or using backup-as-a-service (BaaS).
Cloud Data Backup Is Divided into Several Categories, Including:
- Public cloud for data backup
Data backup storage is provided by a third-party service (i.e., cloud service provider or CSP).
- Private cloud for data backup
Data is backed up to different servers within a company’s firewall, either onsite or at a secondary data center. - Hybrid cloud for data backup
Data backup storage is split between private and public clouds for local and offsite storage. - Cloud-to-cloud (C2C) for data backup
C2C data backup is for data on SaaS platforms. Since the data usually only exists in the cloud, it is backed up from the SaaS cloud to another cloud for storage.
Data Backup and Storage Technology
Another consideration for data backup is storage. The choice of storage technology for data backup depends on several factors, including the size of the backups, setup complexity, portability requirements, security specifications, budget, and the location of data backups.
Following are some commonly used storage technologies for data backup.
- Cloud storage
- Direct-attached storage (DAS)
- External hard drives
- Tape media
- Network attached storage (NAS)
- Optical storage media
- Redundant array of independent disks (RAID)
- Software-defined storage
- Storage area networks
Data Backup vs. Data Archiving
Backup vs. archive are often used interchangeably, but they are not the same.
| Data Backup | Data Archiving |
| Built for administrators and end-users to quickly find and restore data | Limits access to privileged admins or authorized users |
| Data can be changed or overwritten | Data cannot be altered or deleted |
| Designed specifically to prevent data loss | Designed for long-term data storage |
| One of multiple copies of data | The only copy of data |
| Protects your active and inactive data | Retains inactive or older data |
| Requires rapid retrieval | Retrieval time not important |
| Short-term retention | Long-term data retention |
| Supports rapid recovery of active production files | Stores inactive production data that requires retention |
Data Backup
A data backup is a copy of production data (active and inactive) that is made on a regular basis to protect against data loss. The frequency of data backups is based on a schedule or when changes are made to the data.
Data backups can include data as well as system and application files. The objective of data backup strategies is to have a copy of anything in current use that is needed for day-to-day operations.
Data backups have additional uses. For example, a user can go to a backup to retrieve an earlier version of a file because it contains something that’s no longer in the current file. A powerful use case for data backup is ransomware recovery—the ability to restore encrypted or compromised systems.
Data Archive
A data archive is a copy of inactive or older data that’s made for long-term storage and reference. The files stored in a data archive are generally no longer in use, not changing frequently, and not required regularly. The original data may or may not be deleted from the source system after the archive copy is made and stored, though it is common for the archive to be the only copy of the data.
Data archives have multiple purposes. They can provide a permanent record of documents or other records for internal use and to meet information retention requirements related to compliance. A data archive can also be free up space on more expensive production data backup systems.
Good data governance puts controls on data archives and data backups. Rules are set to determine which files are moved to data archives and when. In addition, retention rules are set for files, dictating how long they should be held as well as when and how they should be destroyed.
Ensure Success with Data Backup Policies
The importance of data backup policies cannot be overstated. All the solutions in the world are of no use unless there are processes and procedures that dictate how they should be used. Data backup policies provide crucial guidance that governs:
- What data (files and folders) to back up
- What compression method to use, if any
- How often to run data backups
- What type of backups to run
- What kind of media should be used to store the backups
- Where to store the backup data
- How long data should be retained
Developing and implementing data backup policies will ensure data availability, protection, and resilience.
Egnyte has experts ready to answer your questions. For more than a decade, Egnyte has helped more than 16,000 customers with millions of customers worldwide.
Last Updated: 13th April, 2022




