
How Egnyte Uses Rate Limiting to Dynamically Scale
Egnyte stores, analyzes, organizes, and secures billions of files and petabytes of data from millions of users. On average, we observe more than a million API requests per minute. As we scale, we have to address challenges associated with balancing throughput for individual users and delivering exceptional quality of service.
For example, some Egnyte hosted content that is publicly shared (via our share file and folder links feature) can suddenly go viral. While the service elastically scales to respond to such events, we need to preserve the global responsiveness of the application for all customers. Dynamically detecting unusual request patterns and applying rate limits is one way to handle such challenges.
Let's take a closer look at rate limiting and how we use it at Egnyte.
What Is Rate Limiting?
Rate limiting is used to control the rate of requests sent or received by a network interface controller.
We encounter rate limiting in our everyday lives as we consume data through applications such as video streaming services. Some services restrict subscribers to only allow concurrent streaming on a specific number of devices.
We can divide rate limiting into the following types:
- HTTP request rate limiting
- Limiting concurrent requests
- Bandwidth or egress/ingress rate limiting
HTTP Request Rate Limiting
We started by analyzing options that were readily available and could be quickly deployed. Of the multiple available options, we selected Kong as our API gateway. Kong is great for rate limiting with standard HTTP attributes such as rate limiting requests per second or minute based on the HOST header.
There were a few limitations with the open source request rate limiting plugin provided by Kong:
- Kong requires one rule per host header. We have a multi-tenant stack, and this is a problem for us
- Limited support for rate limiting based on other headers like user agents or custom headers
- Limits cannot be fetched from an external repository.
Our requirements are a bit more complex:
- We have desktop clients, web clients, and mobile clients. We want to block requests on different combinations of headers
- We want to set dynamic request limits per tenant set via a machine learning model, so our rate limiting module should have the ability to fetch limits dynamically from an external repository or service
- Support for a dry-run, warning mode where it will just log the requests that would have been blocked
The code snippet below depicts the kind of flexibility we are looking for while configuring these rules.
{
"rule_name": "ratelimit_on_client_id",
"rule":{
"rate_limit_by": [
{ "type":"Header", "name":"Host" },
{ "type":"Header", "name": "X-Egnyte-Client-Id" },
{ "type":"IP", "extract_from_header": "X-Forwarded-For" },
{ "type":"REQUEST_URI"}
],
"include_filter": [
{ "type": "Header", "name": "User-Agent", "pattern": “..." }
],
"exclude_filter": [
{ "type": "Header", "name": "User-Agent", "pattern": "..." }
]
}
}
This rule will take into account a combination of values parsed from the Headers “Host”, “X-Egnyte-Client-id”, and “IP” (parsed from the “X-Forwarded-For” header). It will also take into account the “REQUEST_URI”. We will configure the rule to exclude all others, even if they match the other three combinations. Additionally, we add safeguards for specific traffic sources: an “include_filter” parameter to ensure that it will only apply to the traffic generated from a particular source. This is much needed since Egnyte allows its customers to use the platform from multiple access points.
Given the circumstances, we rolled up our sleeves and started developing our own solution. It’s a custom plugin built in LUA.
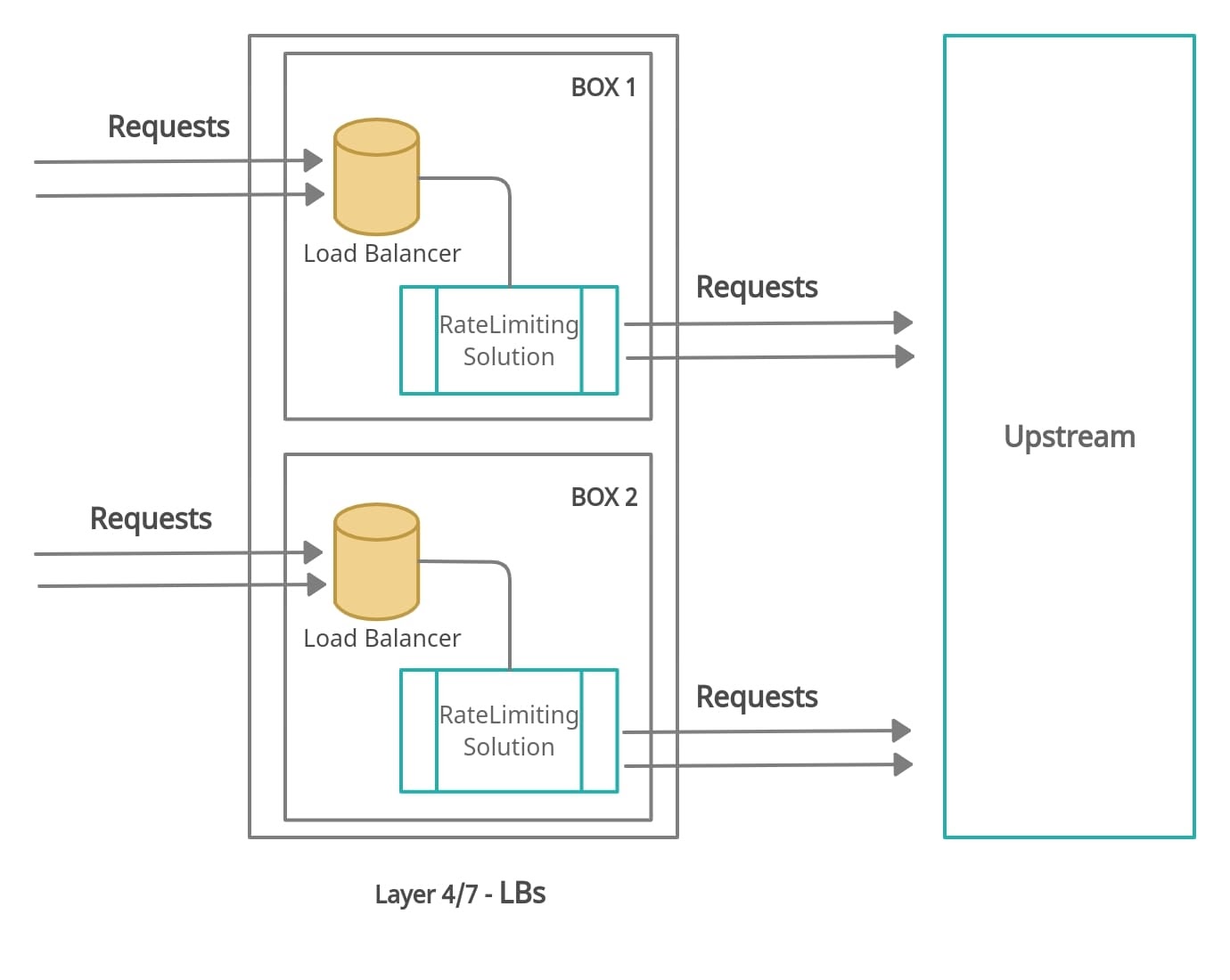
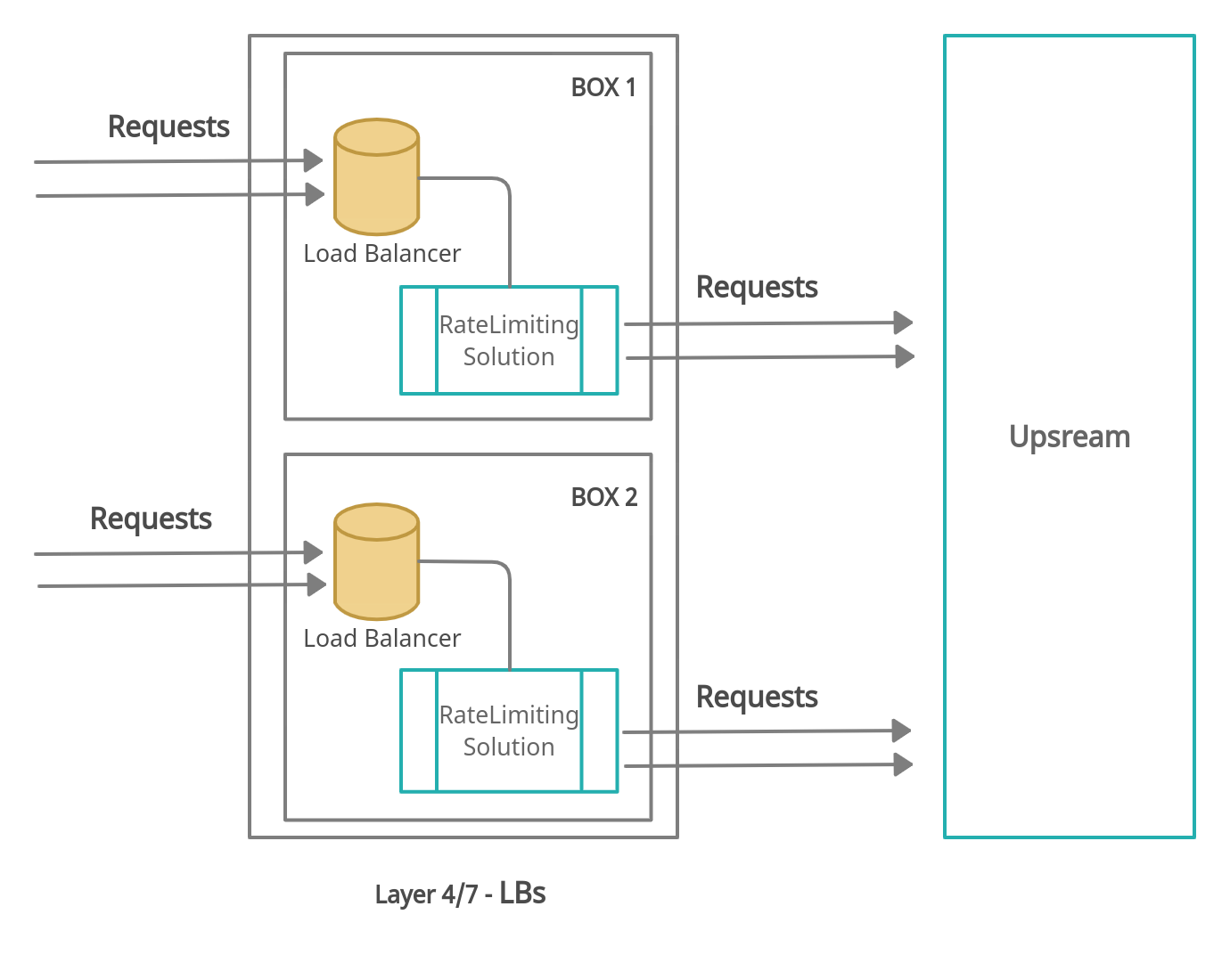
Our rate limiting module is deployed behind a set of load balancers that terminates user traffic. Every request coming into this stack is then routed to the OpenResty proxy that hosts our rate limiting module. The load balancers are configured to automatically disable the rate limiting module if the health checks on the rate limiting module fail. This is to allow for a graceful degradation in case of an unanticipated outage in the rate limiting layer. Any optional subcomponents that fail should get out of the way by auto-disabling the features managed by these components while alerts are triggered for our SRE team.
Limiting Concurrent Requests
One of the key metrics of any high-scale system is the number of requests being processed at any given time. Currently, running requests provides an interesting insight into the state of the system and could be an indication of unusual activity or some upstream component slowing down.
OpenResty allows interception of the request at various points:
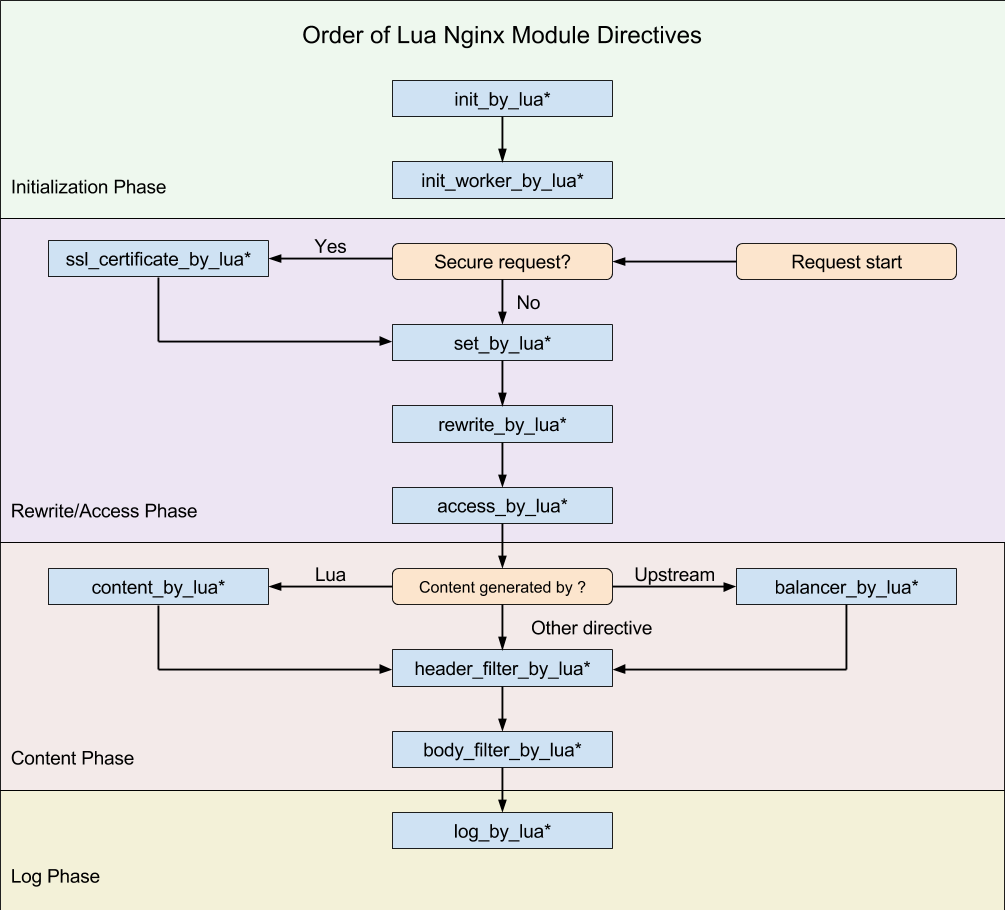
Let’s just focus on access_by_lua and log_by_lua in the access phase and log phase.
According to our requirements, we want to monitor the concurrent requests by:
- The type of request
- Its Context URI
- Ingress and egress points of the request
To keep things simple, we should know the start and end of the request to monitor a single request. Requests start in the rewrite phase in this flow, with access_by_lua acting as the door to enter the upstream. This is where we consider that request has begun.
At this stage, there are two problems:
- Identifying unique requests
- Storing the number of all concurrent requests served across all the OpenResty servers
For every new request, a unique ID is assigned as requests will spread across a cluster of servers, and each request needs to be logged. For this we need an external datastore. We picked Redis—a fast and distributed in-memory counter store—for this purpose. So we need to intervene in the request flow and store its data in Redis.
A small proof-of-concept in production revealed that hitting Redis for every request start and finish will not scale at our volumes. Slowness in Redis operations was leading to slowness in all request flows. To resolve this, we started digging inside OpenResty, various LUA libraries, finally coming up with the approach of storing these in shared memory eventually backed by Redis counters.
Shared memory takes away the load on Redis by buffering the data in local memory with an update to Redis in bulk every few seconds. This heavily reduces the load on Redis, thus helping scale the solution. An obvious downside to this approach is that Redis now has a delayed snapshot of the system state instead of a real-time picture.
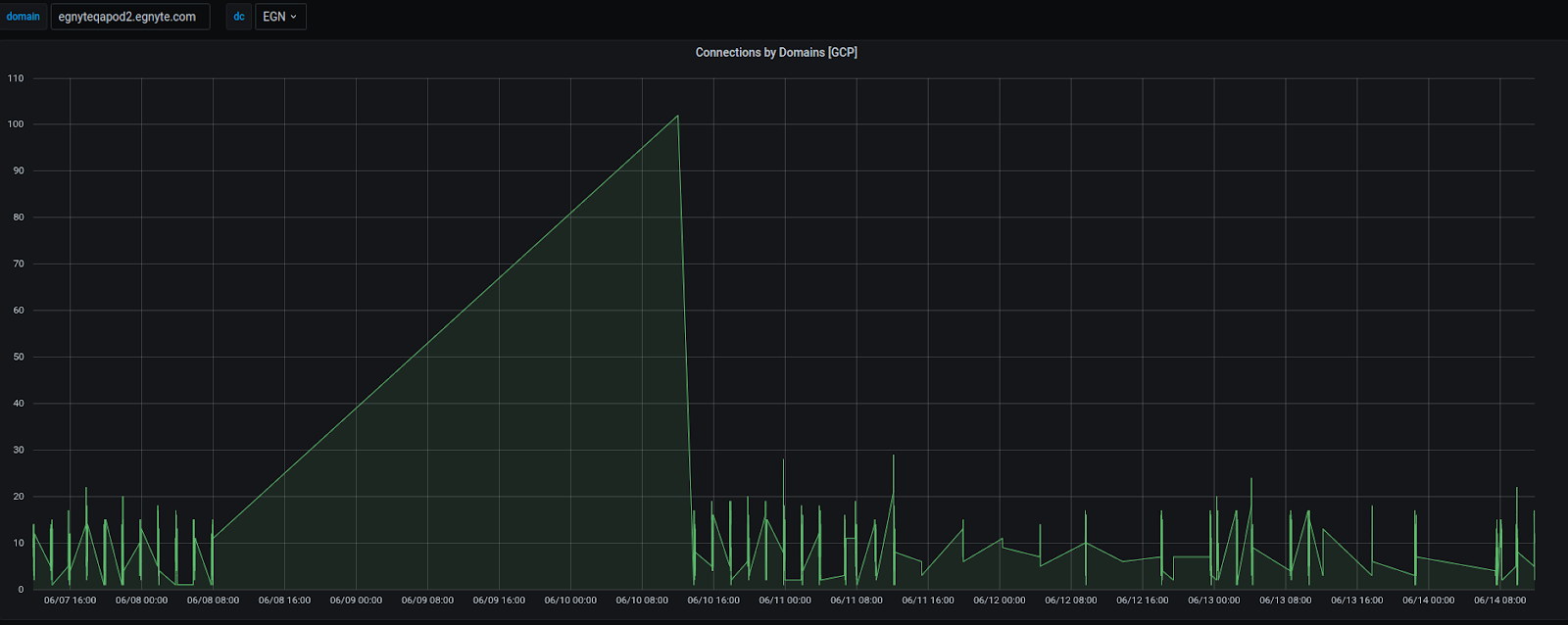
When deployed in prod, we could see the state of our production connections as follows:

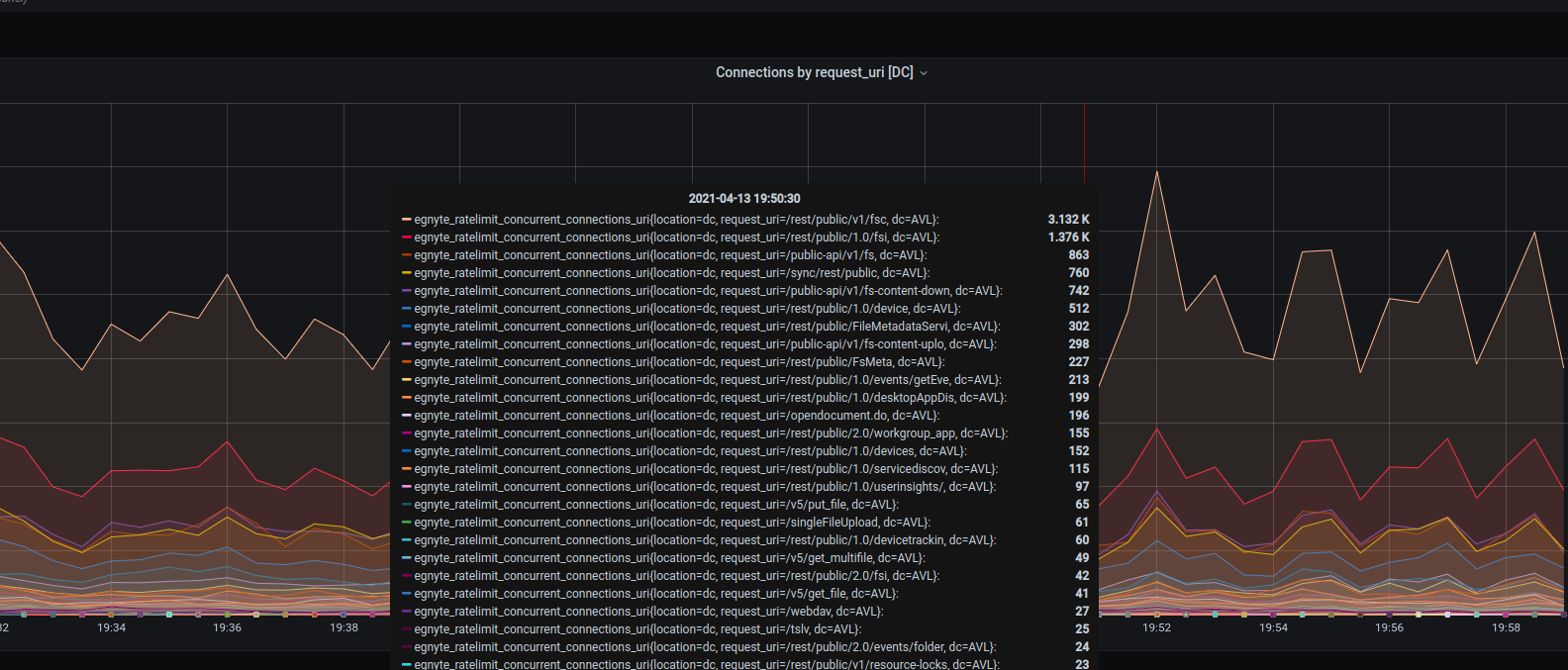
Download Capping/Rate Limiting
Since the Egnyte platform is effectively a distributed file system, there are a lot of namespace accesses, ingress (upload) and egress (download) operations. These accesses come from a variety of clients such as web UI, desktop, mobile, and public API. Since most tenants use more than one access point, it is crucial to understand the traffic first.
Factors that need to be considered before rate limiting traffic include:
- Traffic source, i.e., what type of client is this?
- Specific request context that should be rate-limited (URI, User-agent, etc.)
- Traffic type (namespace operations, downloads, uploads)
As an example, the download rate limiter heavily uses NGINX maps to match the given constraints. Maps also help keep latency down, which is essential.
Below is the example of one NGINX map, where we specify the download constraint.
```
map $http_x_egnyte_useragent $dl_wg_limit {
volatile;
default 0;
EgnyteDesktop 1073741824;
}
```
We use these maps to store different types of constraints. We also use them for features like increasing the overall limits or limits for specific tenant types by N%.
As requests arrive, we increment the egress and ingress byte counters in NGINX memory maps using the OpenResty hooks explained above. The counters are then frequently synced with Redis so every node in the cluster uses the correct value when it makes a decision to reject a request.
The diagram below depicts the request flow in detail.
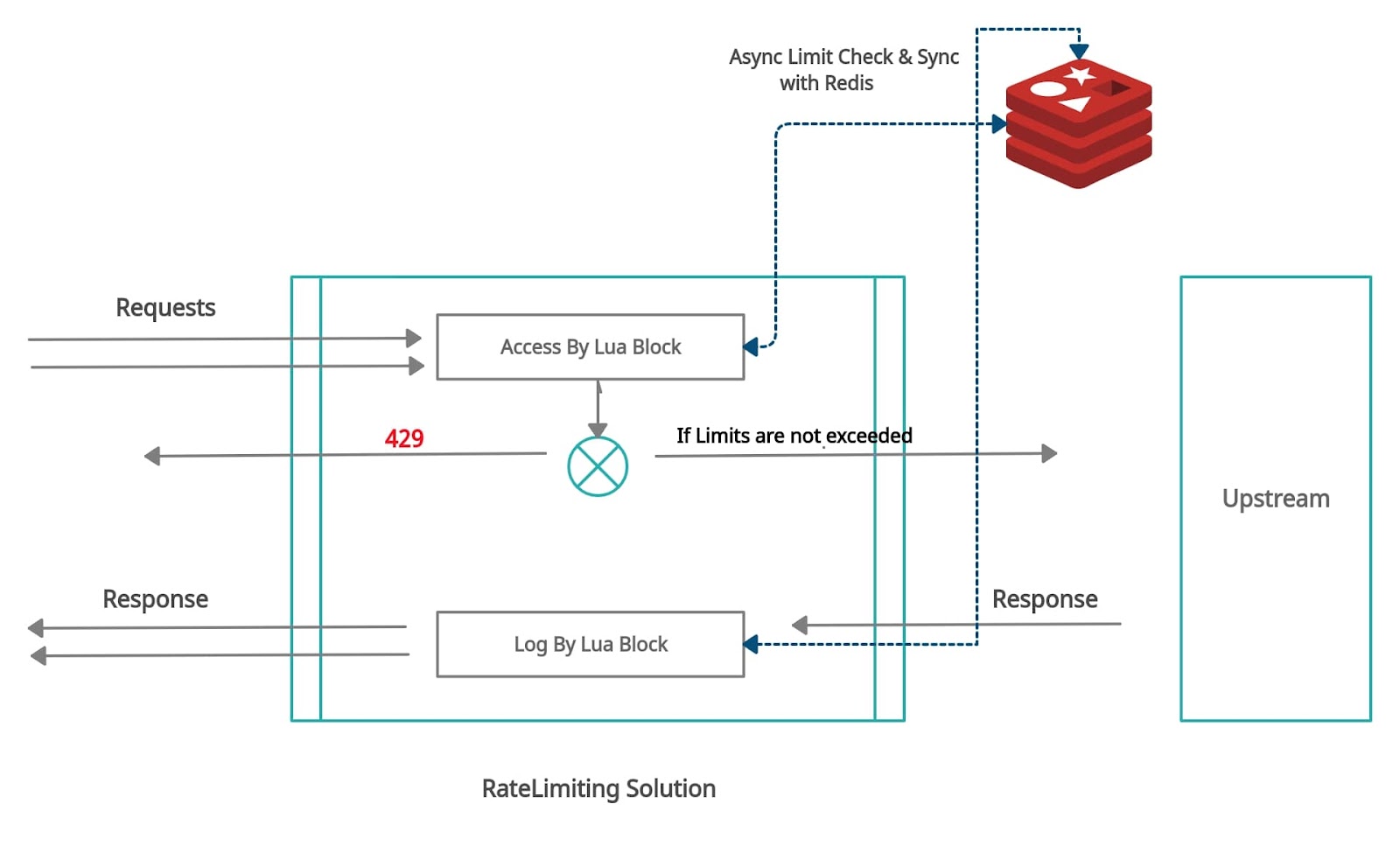
This service, which is hosted within Kubernetes and leverages the Python Celery framework, also queries the metrics from Redis and loads those in a time-series database for indexing. These metrics are then made available for visualization in Grafana.
Last but not least, this solution could devolve into hard-coded configurations. But to manage our infrastructure as code, we use Puppet, a configuration management tool, to change OpenResty maps, limits, and to enable or disable operation for tenants.
We hope that this discussion of our product selection and implementation choices adds to the extensive discussion around rate limiting options and provides some guidance on approaching such projects.






