Part 1: How Egnyte Built its Turnkey Retrieval Augmented Generation Solution
The Egnyte platform houses a lot of data. To enable users to make the most of this asset, we need to help them efficiently retrieve information.
Traditional search interfaces do a decent job of retrieving information directly related to query keywords, often presenting results in a list format without additional interpretation or synthesis. However, a newer technique called Retrieval Augmented Generation (RAG) can not only retrieve relevant information but also integrate and synthesize it through generative AI processes to produce even more coherent and contextually enriched responses.
However, deploying a RAG system is not without its challenges, especially for mid-sized organizations. One significant hurdle is the quality and management of the data used for retrieval, as this information can be vast and in varied formats, often spread across multiple documents and folders. Integrating RAG with existing IT infrastructure and user-facing workflows present another layer of complexity, requiring careful planning and execution. Furthermore, ensuring that the system scales efficiently while maintaining performance, and addressing key concerns related to privacy, transparency, and accuracy are also paramount.
In this blog, we will explore how Egnyte enables users to answer queries over complex documents, without having to build their own complex data pipelines. Learn more about the strategies we’re undertaking to guide models to produce fact-based responses, ensuring that the information they generate is reliable and grounded in reality. Additionally, we will discuss how we balance cost-efficiency with high-quality output, adapt, and optimize RAG processes for diverse datasets and various business domains.
Business Objective
The Document Q&A feature was our first foray into moving from a mere document retrieval approach to retrieving the precise answer to a user’s question. This involved computing the vector representations of the document on the fly and using a FAISS (Facebook AI Similarity Search) index to retrieve the relevant chunks from that document, and sending them to a generative AI model for Q&A.
This approach, however, did not scale for larger documents and for cases where the complete answer had to come from more than one document. In the latter example, we wanted to let non-technical business users mark any Egnyte folder as a "Knowledge Base" to base their AI queries around. For example, a HR Admin might want to designate an HR Knowledge Base containing policy documents, so that employees can seek answers on HR policy related queries.
We also envision Knowledge Bases being created for more specialized fields as well. For example, a user working in Architecture, Engineering, and Construction (AEC) industry might want to ask a Building Codes Knowledge Base a question like “How many parking spaces need to be van-accessible?” or a Safety Standards Knowledge Base “What type of fall prevention is required while working on a roof”. As codes and standards vary widely by locale and project type, the responses would need to be grounded in a company’s owned (or licensed) document libraries – and this information is not readily available on the public web or through public GPT models.
Solution Design
Scaling to an Enterprise Knowledge Base
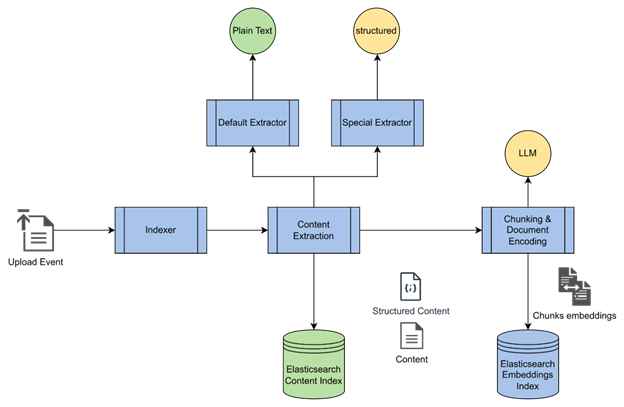
To be able to perform multi-document Q&A over 100,000 documents, we needed to extract the content from all the relevant documents, which involved different file types like PDF, MS Office, and Images, build a BM25 index, pre-compute the vector representations, and perform a hybrid search to filter out the relevant documents.
These documents were further broken and filtered to get the relevant portions from within these documents, and which is then used in answer generation.
So retrieving only the relevant information from so many documents was critical to get a correct and complete answer, but at the same time, it should honor Egnyte’s permission model, and prevent inaccessible information from being used in answer generation.
We used the RAG approach presented by?? Lewis et al, 2020. This helped us to combine the knowledge of the pre-trained language model with the knowledge contained in the enterprise knowledge base, so that the generated answer is up to date and relevant to the customer.
Typically, RAG involves the following steps: -
- Extracting the content from a file.
- Generating the vector representation of the content and building a dense vector index.
- Searching for the top K documents using the Query vector.
- Combining the retrieved content with the query to create a Q&A prompt for answer generation.
The remainder of this blog focuses on the “Retrieval” part of our RAG pipeline and the “Augmentation and Generation” part would be covered in the following blog.
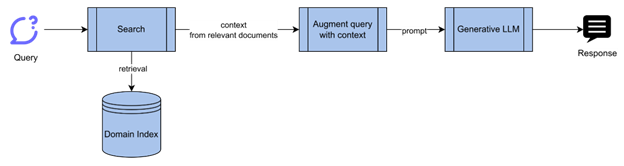
At a high level, the scheme of things in our pipeline appears as below:
- The Egnyte collaboration platform takes “File Upload” events and passes it on to a Multi-doc Q&A orchestrator.
- The orchestrator initiates the indexing pipeline and publishes the event to the indexer module.
- The Indexer calls the content extractor to extract the content from the document and indexes it into a keyword index.
- It then calls the embeddings generator to generate the embeddings for the content and indexes them into an embeddings index.
When a user initiates a conversation on a folder, the orchestrator searches the relevant information through the Search API and calls the Q&A service to generate the answer.

Retrieving Relevant Documents
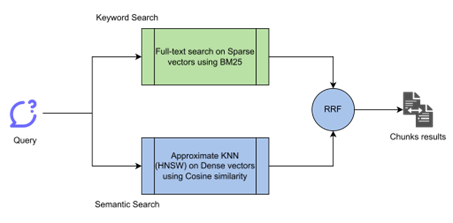
A quick and easy way to search for relevant documents is to use the traditional keyword-based search which uses the BM25 ranking function.
BM25 is based on term frequencies but penalizes the terms that are common.
We were able to easily plug our existing Elasticsearch infrastructure into the search pipeline.
Along with the file’s content, we index other metadata related to files and folders like domain metadata, file/folder name, path, creation date, created by, and more, so the query can be matched with any of the metadata of a document.
Understanding the Contextual Meaning of the Query
Keyword based search may be useful in exact matches or queries with fewer terms but does not capture the complete context of the user's query.
A Semantic search, however, can capture the underlying concept of the query and find results that are semantically closer to the query.
Combining keyword search (sparse retrieval) with semantic embedding (dense retrieval) proved superior to just using one or the other, blending metadata and terms with language semantics. ?Sawarkar et al. 2024, empirically demonstrated that hybrid query approach employing KNN (K nearest neighbor) search in dense vector index, along with various combinations of Match Query in BM25 index, achieved higher retrieval accuracy than the BM25 queries alone. The highest top 10 retrieval accuracy on NQ (Natural Questions) dataset was 88.66 from hybrid query compared to 86.26 from BM25 query.
To be able to perform a semantic search, we evaluated a couple of Vector databases and went ahead with Elasticsearch because it gave us the advantage of quicker time to market owing to the expertise that we have built over the years managing this in-house hosted cluster.
Elasticsearch uses Hierarchical Navigable Small World graphs (HNSW) structure, a proximity graph-based structure, to store embedding vectors.
The proximity is defined by the dot product similarity between two vectors.
We index the chunk offsets along with its embedding. These offsets are used later to fetch the chunk text at these positions and construct the prompt using these texts.
Encoding Context Into Vectors
Text, words, sentences, or chunks need to be encoded into vectors so that they can be compared in a vector space. The advantages of semantic search come with the computational cost of generating the embeddings and comparing two vectors.
Embeddings generation is computationally expensive and needs to be scaled well in self-managed hosting. We evaluated various open source models, but settled on a cloud-hosted Large Language Model (LLM) to generate text embeddings for quicker time to market. However, we are limited by the cloud provider’s quota and cost.
Retrieving Only Relevant Chunks
A typical knowledge base could have thousands of documents of varying sizes. This is where an efficient retrieval becomes important to filter out the irrelevant information.
The results from vector search are joined with that of keyword search so that the chunks are filtered by the metadata in the query.
Egnyte also has a role-based permissions model and we need to make sure that the Q&A does not use the content from a file which is not accessible to the user to generate the answer. This is taken care of by post-filtering the vector search results with the user’s permissions.
Limiting Noise in Context
The embeddings vector can only represent a limited amount of content. So, the document has to be chunked and then embeddings are created per chunk.
A content document in the keyword index would have N chunk documents in the embeddings index. Chunking could be done based on fixed sizes or on logical boundaries like paragraphs. We chunk the files by size and have evaluated different chunk sizes based on the quality of answer generation.
During Q&A, these embeddings models can take up to a limited context length, so only relevant chunks are passed in the prompt. Chunks should be small to not have irrelevant content, but at the same time, they should be large enough to not lose their semantic boundary.
Searching the Entire Index
Since, a brute force K Nearest Neighbor (KNN) search would be computationally impractical, we use the Approximate Nearest Neighbor (ANN) search to find KNN to a query vector. In contrast to a KNN search, the ANN search compromises on some accuracy in favor of better response time on larger datasets.
The Elasticsearch ANN API gets N nearest neighbor candidates from each shard and returns K most similar results across the shards. The search accuracy can be increased with a higher N but at lower speed.
Embeddings Generation and Storage Cost
The indexing pipeline has to be triggered for every file uploaded causing storage and other infrastructure costs to quickly go out of hand. If a 1 MB file is split into 2,000 chars chunks, it would result in around 250 chunks, and if each chunk is encoded into an embedding vector of 1024 dim, with each vector consuming 4 KB of memory, in total the file embeddings would consume 1 MB, and on-disk size in Elasticsearch cluster would be much more to index this vector document.
Elasticsearch does support quantization to reduce the memory required to store embeddings, in which case it reduces the memory by 1/4th by quantizing them to integers instead of floats. We did not use quantization to avoid the loss in accuracy.
Metadata Filtering for Vector Search
Since Vector search is performed on the entire index for that user, it needs to be joined with the results from keyword search filtered on domain metadata, so that only relevant results are returned for the query.
Since ANN search is probabilistic, it could result in not finding any documents that match the metadata filters, in which case it is used with a larger value of K, which could slow the search but still return the results successfully.
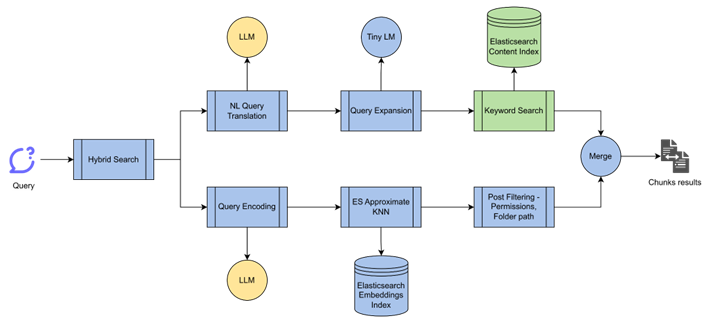
Natural Language Queries With Keyword Search
To provide a conversational style interface for Q&A, we need to allow queries in natural language. But these queries need to be translated to various metadata filters like date, type, etc., to perform keyword search.
We use a generative LLM to translate natural language queries into parameters for our keyword search function.
Increasing Recall in Keyword Search
While keyword search guarantees exact matches, it has lower recall because it fails to match out of vocab terms. To increase recall, we can either index the documents with additional fields having related terms that are not present in the document, or expand the query to have terms related to the query.
Since index time tagging would require re-indexing of existing documents, we use query expansion to generate additional terms to be searched with the query. We have an in-house developed Machine Learning (ML) model which builds a co-occurrence matrix from the content and generates terms related to the query. Since this model is built on the user’s content, it is able to generate context specific terms.
Combining the Results From Different Ranking Functions
Since keyword search results are ranked using the BM25 function, and semantic search results are scored using dot product, we needed a way to combine these results into a single list and produce a final rank for each result.
We have used the Reciprocal Rank Fusion (RRF) method proposed by Cormack et al. 2009 which sums the reciprocal of rank for a document from each list to produce a final rank for that document. The final score is combined from keyword search and semantic search based on a weight. Final score = keyword score * (1-weight) + vector score * weight.
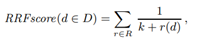
Conclusion
This concludes the “Retrieval” part of this blog series, we would continue with a deep dive on the “Augmentation and Generation” part in our next blog, where we would cover the chunk reranking, prompt construction, citations, and much more.