
Understanding SimCLR, a framework for contrastive learning
This post was originally published on zablo.net
Transfer learning and pre-training schemas for both NLP and Computer Vision have gained a lot of attention in the last months. Research showed that carefully designed unsupervised/self-supervised training could produce high-quality base models and embeddings that greatly decrease the amount of data needed to obtain good classification models downstream. This approach becomes more and more important as the companies collect a lot of data from which only a fraction can be labeled by humans—either due to the large cost of the labeling process or some time constraints.Here I explore the SimCLR pre-training framework proposed by Google in this arxiv paper. I will explain the SimCLR and its contrastive loss function step by step, starting from a naive implementation followed by a faster, vectorized one. Then I will show how to use SimCLR's pre-training routine to build image embeddings using EfficientNet network architecture, and finally, I will explain how to build a classifier on top of it.
TL;DR
This post covers:
- understanding the SimCLR framework
- from-scratch explanation & implementation of SimCLR's loss function (NT-Xent) in PyTorch
- pre-training image embeddings using EfficientNet architecture
- training a classifier using transfer learning from the pre-trained embeddings
Understanding the SimCLR framework
In general, SimCLR is a simple framework for contrastive learning of visual representations. It's not any new framework for deep learning, it's a set of fixed steps that one should follow in order to train good-quality image embeddings.I drew a schema that explains the flow and the whole representation learning process.
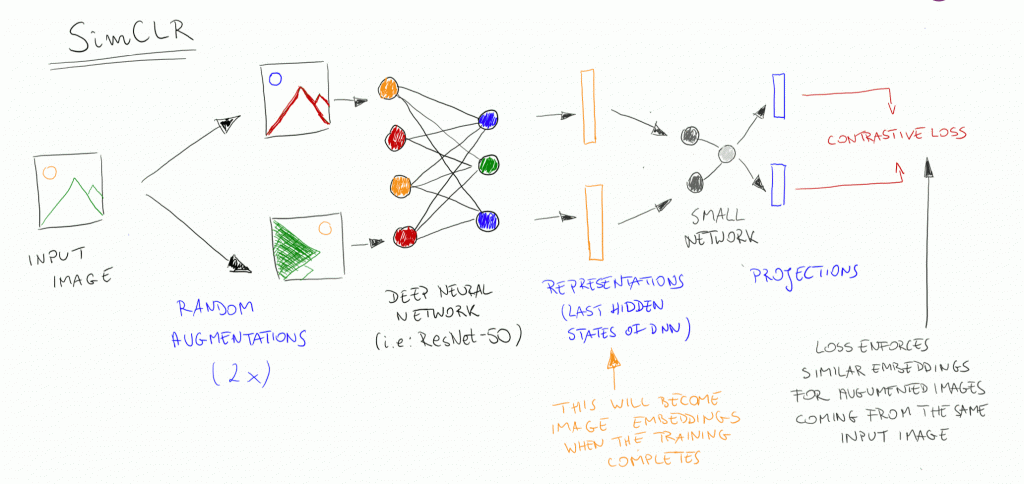
The flow is as follows (from left to right):
- Take an input image
- Prepare 2 random augmentations on the image, including rotations, hue/saturation/brightness changes, zooming, cropping, etc. The range of augmentations as well as analysis of which ones work best are discussed in detail in the paper.
- Run a deep neural network (preferably a convolutional one, like ResNet50) to obtain image representations (embeddings) of those augmented images.
- Run a small, fully connected linear neural network to project embeddings into another vector space.
- Calculate the contrastive loss and run backpropagation through both networks. Contrastive loss decreases when projections coming from the same image are similar. The similarity between projections can be arbitrary, here I will use cosine similarity, same as in the paper.
Contrastive loss function
The theory behind contrastive loss function
One can reason about contrastive loss function from two angles:
- Contrastive loss decreases when projections of augmented images coming from the same input image are similar.
- For two augmented images: (i), (j) (coming from the same input image—I will call them a "positive" pair later on), the contrastive loss for (i) tries to identify (j) among other images ("negative" examples) that are in the same batch.
The formal definition of the loss for a pair of positive examples (i) and (j) is as follows:
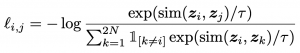
The final loss is an arithmetic mean of the losses for all positive pairs in the batch:
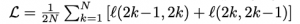
(keep in mind that the indexing in l(2k-1, 2k) + l(2k, 2k-1) is purely dependent on how you implement the loss—I find it easier to understand when I reason about them as l(i,j) + l(j,i)).
Contrastive loss function - implementation in PyTorch, ELI5 version
It's much easier to implement the loss function without vectorization first, and then follow up with the vectorization phase.
Explanation
Contrastive loss needs to know the batch size and the temperature (scaling) parameter. You can find details about setting the optimal temperature parameter in the paper.My implementation of the forward of the contrastive loss takes two parameters. The first one will be a batch projection of images after the first augmentation, the second will be a batch projection of images after the second augmentation.Projections need to be normalized first, hence:All representations are concatenated together in order to efficiently calculate cosine similarities between each image pair.Next is the naive implementation of l(i,j) for clarity and easiness of understanding. The code below implements the equation almost directly:
Then, the final loss for the batch is computed as an arithmetic mean of all combinations of positive examples:Now, let's run it with verbose mode to see what's inside.A few things happened there, but by going back and forward between the verbose logs and the equation, everything should become clear.The indexing jumps by batch size (first l(0,3), l(3,0)then l(1,4), l(4,1)because of the way the similarity matrix was constructed. First row of the similarity_matrixis:Remember the input:Now:1.0000is the cosine similarity between I[0] and I[0]([1.0, 2.0] and [1.0, 2.0])-0.1240 is the cosine similarity between I[0] and I[1]([1.0, 2.0] and [3.0, -2.0])-0.0948is the cosine similarity between I[0] and J[2]([1.0, 2.0] and [2.8, -1.75])... and so on.Let's see if the loss decreases if the similarity between first image projection increases:Indeed the loss decreases! Now I will follow up with the vectorized implementation.
Contrastive loss function - implementation in PyTorch, vectorized version
The performance of naive implementation is really poor (mostly due to the manual loop), see the results:Once I understood the internals of the loss, it's easy to vectorize it and remove the manual loop:The difference should be zero or close to zero (< 1e-6 due to fp arithmetics). Performance comparison:Almost 4x improvement, it works.
Pre-training image embeddings using SimCLR with EfficientNet
Once the loss function is established and understood, it's time to make good use of it. I will pre-train image embeddings using EfficientNet architecture, following the SimCLR framework. For convenience, I've implemented a few utility functions and classes that I will explain briefly below. The training code is structured using PyTorch-Lightning.I will use a great EfficientNet [https://arxiv.org/abs/1905.11946] implementation by Luke Melas-Kyriazi from GitHub, already pre-trained on ImageNet (transfer learning inception!). The dataset I choose is STL10 (from torchvision) as it contains both training and unlabeled splits for unsupervised / self-supervised learning tasks.
My goal here is to demonstrate the whole SimCLR flow from start to finish. I had no intent to reach new SOTA with the presented configuration.
Utility functions for image augmentations
Training with SimCLR produces good image embeddings that are not affected by image transformations. It happens because, during training, various data augmentations are done to force the network to understand the contents of the images regardless of i.e. the color of the image or the position where the object in the image is placed.SimCLR's authors say that composition of data augmentations plays a critical role in defining effective predictive tasks and also *contrastive learning needs stronger data augmentation than supervised learning*. To sum this up: when pre-training image embeddings, it's good to make this task difficult for the network to learn by strongly augmenting the images in order to generalize better afterwards.
I strongly advise reading the SimCLR's paper and its appendix as they did ablation studies on which data augmentations bring the best effects on the embeddings.
To keep this blog post simple to go through, I will mostly use built-in Torchvision's data augmentations, with a single additional one - random resized rotation.A brief look on the transformation results:

Automatic data augmentation wrapper
Here I've also implemented a utility dataset wrapper that automatically applies random data augmentations whenever an image is retrieved. It can be easily used with any image dataset as long as it follows the simple interface of returning tuple with (PIL Image, anything). This wrapper can be set to return a deterministic transformation with the debug flag set to True. Note that there is a preprocess step that applies ImageNet-originated data standardization as I'm using already pre-trained EfficientNet.




SimCLR neural network for embeddings
Here I define the ImageEmbedding neural network which is based on EfficientNet-b0 architecture. I swap out the last layer of pre-trained EfficientNet with identity function and add projection for image embeddings on top of it (following the SimCLR paper) with Linear-ReLU-Linear layers. It was shown in the paper that the non-linear projection head (i.e Linear-ReLU-Linear) improves the quality of the embeddings.Next is the implementation of a PyTorch-Lightning-based training module that orchestrates everything together:
- hyper-parameters handling
- SimCLR ImageEmbedding network
- STL10 dataset
- optimizer
- forward step
As the PretrainingDatasetWrapper I've implemented returns a tuple of: (Image1, Image2), dummy class, the forward step for this module is straightforward—it needs to produce two batches of embeddings and calculate the contrastive loss function:Initial hyper-parameters. Batch size of 128 works fine with EfficientNet-B0 on GTX1070. Note that I've limited the training dataset to first 10k images from STL10 for convenience of running this blogpost in the form of a Jupyter Notebook / Google Colab.
Important! SimCLR greatly benefits from large batch sizes—it should be set to as high a value as possible given the GPU / cluster limits.
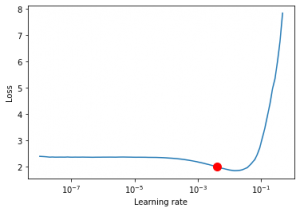
Finding a good initial-learning rate using the LRFinder algorithm
I use pytorch-lightning's built-in LRFinder algorithm to find an initial learning rate.
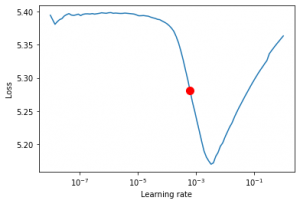
I also use W&B Logging to keep track of my experiments:After the training finishes, embeddings are ready for usage for the downstream tasks.
Building an image classifier on top of SimCLR embeddings
Once the embeddings are trained, they can be used to train the classifier on top of them—either by fine-tuning the whole network or by freezing the base network with embeddings and learning linear classifiers on top of it—I show the latter below.
Save the weights of a neural network with embeddings
I save the whole network in a form on a checkpoint. Only the internal part of the network will be used later with the classifier (projection layers will be discarded).
Classifier module
Again, I define a custom module—this time it uses already existing embeddings and freezes the base model’s weights on demand. Note that SimCLRClassifier.embeddings are only the EfficientNet part of the whole network used before—the projection head is discarded.
Classifier training code
The classifier training code again uses PyTorch lightning, so I’ll skip the in-depth explanation.
It's worth mentioning here that training with a frozen base model gives a great performance boost during training as the gradients need to be calculated only for a single layer. Additionally, by utilizing good embeddings, only a few epochs are required to reach a good quality classifier with a single linear projection.
Evaluation
Here I define a utility function for evaluating the model using the provided data loader. Note that the transfer between GPU and CPU and storing all results in-memory might be not effective for large datasets!




