Part 2: Audio/Video Search Using Automatic Speech Recognition
Egnyte is making continuous improvements in how users can search for information within their content. With the increasing availability and use of video recording, videos have become a large part of the information, and harnessing it would enable greater efficiency in information retrieval for users.
We use Automatic Speech Recognition (ASR) technology and our full-text search capability to allow users to search through their audio and video content. This is the second part of our two-part blog series on audio and video search using Automatic Speech Recognition (ASR).
The Idea
It all started with an idea that came up during an internal hackathon and was selected to be carried forward for implementation. Soon, engineers from Data Science, Search Platform, and DevOps teams got together to build a proof of concept and successfully demoed it to the audience.
Why do we need audio/video search?
Around 18% of all customer data managed by Egnyte is in the form of audio and video content, so it becomes imperative to make that content searchable, so the user can access their information easily. For media-heavy customers, most of the files are large in size and manually skimming through a long video is a tedious task. Besides improving the efficiency of information retrieval, audio/video search helps users in:
- Saving time to access a piece of information embedded within a video.
- Improving the accessibility of information by enabling individuals with hearing impairment or non-native speakers to access the information easily.
- ASR opens up endless possibilities through AI, such as Video Summarization, Question and Answering, Named Entity Recognition, Semantic Search, Identification of Classified or PII data in speech, and so on.
Architecture
The implementation is an extension of the search services platform and encompasses multiple components. The overall architecture and its components are described below.
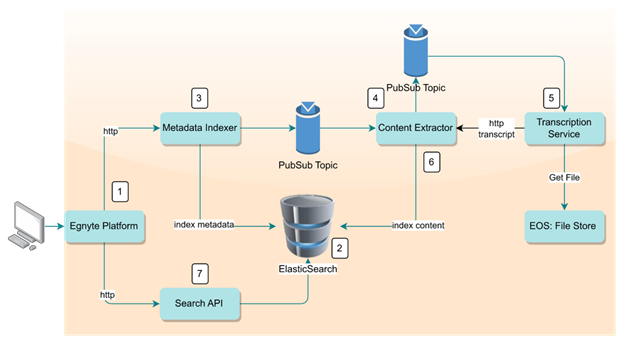
1. Sharing and Collaboration
The Egnyte platform provides an interface to upload files and collaborate with anyone in real-time. The uploaded files are indexed and made searchable so that the user is able to search and retrieve these files later on.
2. Full-text Search Engine
We use Elasticsearch, a distributed search engine built over Apache Lucene. It can scale to a large volume of data and supports varied search queries. Along with other MIME type content, the transcript is indexed and searched through Elasticsearch. Our Elasticsearch clusters hold around 200 TB of indexed content and run on more than 100 data nodes.
3. File Metadata Indexing
The metadata indexer fetches the metadata related to the file such as the file name, owner, created date, etc., and indexes it into Elasticsearch, to make the file searchable using these parameters.
4. File Content Extraction
In this step, the content is extracted from the file and indexed into Elasticsearch. Egnyte supports extraction from all the common file types such as MS Office files, PDF, text files, etc., and it also supports Optical Character Recognition (OCR) on image files. We have optimized this process to exclude abnormally large files, by putting a size limit of 500MB for video files.
5. Automatic Speech Recognition
It is a transcription service written in Python that uses OpenAI’s Whisper model. Whisper is an ASR model trained over multilingual and multitask supervised data that can perform speech recognition, speech translation, and language identification. More information on ASR can be found in Part 1 of this blog series.
6. Indexing the Transcript
The content extraction service subscribes to the indexing events and queues the file to the transcription service. On receiving a callback, it indexes the transcribed text into Elasticsearch. The transcript is stored in a text field and the Elasticsearch Tokenizer breaks the text into words, filtering out stop words, and limiting the number of output tokens. We have limited the number of tokens indexed into Elasticsearch to 10K to avoid cost overruns by extremely large files.
7. Searching Audio and Video files
Once the content is indexed into Elasticsearch, search calls made through the Search API are able to find the file and return the matched content. The Elasticsearch’s simple string query is used to find documents based on the provided query.
Displaying the Matched Text
The transcript generated from the transcription service is in Web Video Text Tracks (WebVTT) format, which looks like:
WEBVTT
00:01.000 --> 00:04.000
<subtitle 1>
00:05.000 --> 00:09.000
<subtitle 2>
When a search is conducted on the content, Elasticsearch returns a matched snippet of text using its default highlighter, which breaks the text into sentences and returns the matched snippet. As a result, the returned snippets do not always have the complete timecode and subtitle pairs. We overcame this problem by using the fast vector highlighter in Elasticsearch that can break the sentence by a boundary character. To do this, it needs to store the terms, positions, and characters offset of the terms in the index, which increases the index size by about 70%. This is something we opted for between cost and usability.
Downloading the Transcript
To be able to access the information spoken around a matched keyword or within a particular time period, we also allow saving the transcript as a text file into an Egnyte Folder. This also allows the user to share the spoken information in a more concise manner.
Deployment and Scaling of Transcription Service
Our infrastructure is on Google Cloud Platform and we use Google Pub/Sub for messaging and Kubernetes for container orchestration. More information can be found in Part 1 of this blog series.
Transcribing Existing Content
Transcription of existing content for users is a humongous task. Egnyte holds around 8 PB of audio/video customer content, and transcribing and indexing it would need multiple GPUs to be able to have them practically searchable, so the existing content is transcribed selectively using GPUs.
Monitoring Indexing
We are saving the application metrics in Prometheus and using Grafana for visualization. We monitor the Indexing process to ensure that indexing is not stuck anywhere and is progressing at a normal rate. Metrics like the number of files indexed by their transcription status, length of the transcript generated by the file extension, and time taken for transcription give a measure of the overall health of the audio/video indexing process.
Customer Feedback
Customer feedback has always been a guiding light for us to improve and do better. We have incorporated feedback from users on the transcript’s view and save usability such as showing the matched text from the transcript with complete timecodes in the search results and formatting the transcript on download in a more readable format.