Building Generative AI Solutions At Egnyte
The rise of Generative AI models has sparked a transformative shift across industries, offering unprecedented capabilities in automating tasks, enhancing decision-making, and fostering innovation. As publicly available tools, these models promise a democratization of technology, suggesting that any company can leverage them to boost efficiency and creativity. However, the reality of integrating and optimizing these AI models for specific corporate needs is far from plug-and-play. While the foundational models are accessible, they often serve as mere starting points. The true challenge lies in tailoring these models to work effectively with a company's unique, private datasets. This customization requires not only a deep understanding of the underlying technology but also a robust framework for innovation and adaptation.
At Egnyte, we've developed innovative strategies to harness GenAI’s full potential while safeguarding our customers’ proprietary data and aligning with specific business processes and goals. In this blog, we will explore how our team has adapted these publicly accessible models in different ways, the hurdles we encountered, and the solutions we developed.
Use Case 1: Document Summarization
At Egnyte, our users interact with a wide range of file types - from PDFs, documents, and spreadsheets to presentations, audio, and video files. Our first foray into Generative AI was to build a feature that would help our users create a succinct summary of these documents, eliminating the need to read through an entire PDF or watch a full-length video. This led to the inception of document summaries using GenAI models.
The majority of GenAI models are text-based, single-modal models. However, there is now a growing availability of multi-modal models that can process various types of data inputs. At Egnyte, we were already extracting text from files through OCR (Optical Character Recognition), audio/video transcription, and other means to power our search engine. We decided to leverage this extracted text to generate concise document summaries using text-based AI models.
But there were a few challenges -
- The size of the documents was more than the context length of most GenAI models.
- GenAI models were heavily ratelimited.
We solved these challenges with the following design.
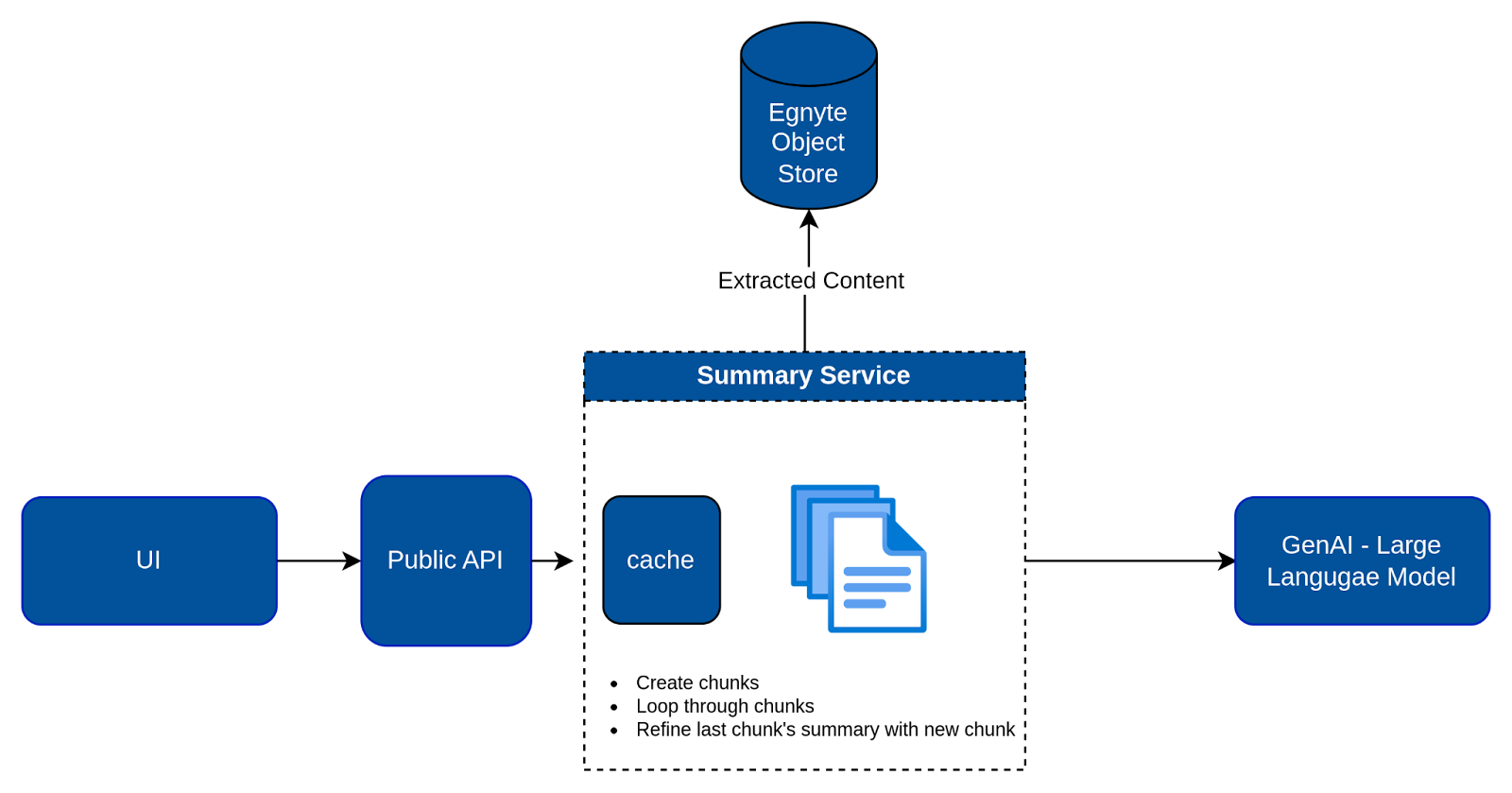
- When a user requests a document summary, the first step involves retrieving the extracted text from the file stored in the Egnyte Object Store (EOS).
- To address the context length limit of the AI model, the text is segmented into several chunks based on the model's context length. Each of these chunks is then processed by the AI model, which incrementally refines the summary of the preceding chunk. This process ultimately results in a comprehensive, consolidated summary.
- The orchestration of refining the summary using these chunks is efficiently managed by the LangChain library's Refine chain.
- Once the summary is generated, it's cached for a predetermined period. This strategy not only addresses the challenge of rate limiting at GenAI models but also enables users to quickly access document summaries.
- Furthermore, we leverage document classification metadata from Egnyte Secure & Govern to tailor the summary, ensuring it's customized to the file's type.
Use Case 2: Document Q&A
The next project problem we tackled led to the development of Document Q&A. Recognizing the need for a more targeted approach to information retrieval, we built a feature that allows users to ask specific questions about a file. This eliminates the need for users to sift through an entire document to find the information they need while still keeping the data safe and secure in their Egnyte repository. With this feature, they can simply ask a question about any file in Egnyte.
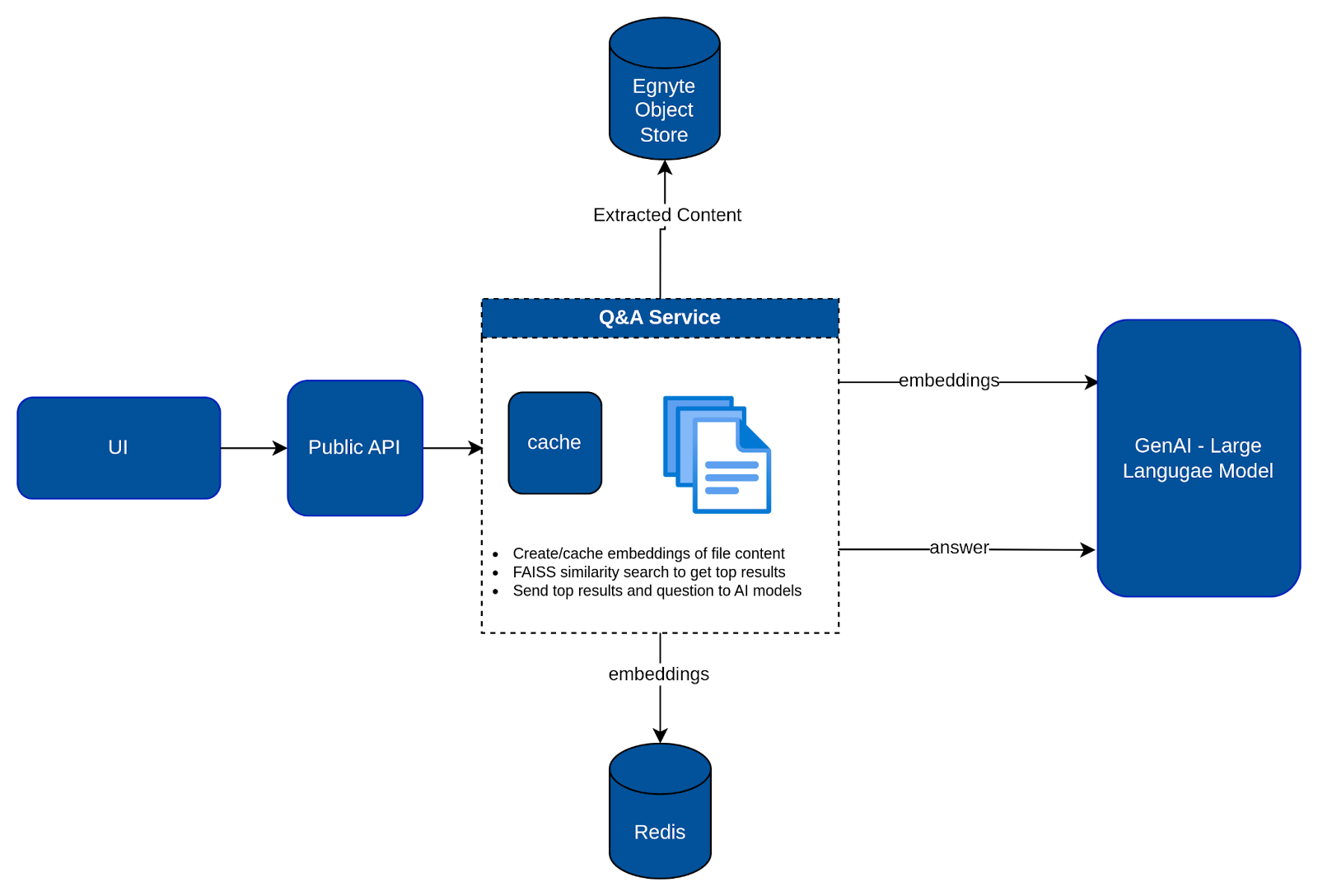
Our initial design leveraged the extracted text that powers Egnyte's search engine. The plan was to send this extracted text, along with the user's question, to an AI model to generate the answer. However, we encountered a challenge with larger documents, as they exceeded the context length limitations of AI models. We also found that dividing the documents and sending multiple requests to the AI did not yield the high-quality answers we strived for.
To overcome these challenges, we turned to RAG (Retrieval Augmented Generation) - an AI framework that enhances AI-generated responses by incorporating an external data source. When a user poses a question, we generate vector embeddings (which we also cache for a predetermined duration). We then employ the FAISS (Facebook AI Similarity Search) library to identify the most relevant sections of text and send them to our AI models for processing.
This approach ensures that our users receive precise and high-quality answers to their questions, regardless of the size or complexity of the document.
Here are the high-level steps involved-
- When a user asks a question, we first check if the vector embeddings of the extracted text are already cached. If not, we generate and cache them.
- We then conduct an in-memory similarity search over these embeddings.
- The top-matched chunks, along with the question, are sent to the GenAI models to generate the final answer, complete with citations.
Use Case 3: “Knowledge Base” Q&A
The natural evolution of our Document Q&A feature was to extend it to sets of documents, which we call “Knowledge Bases.” However, the challenge of generating and storing embeddings for all documents presented a significant cost hurdle, especially when dealing with petabyte-scale data.
To address this, we've introduced a solution that allows users to select a folder containing homogeneous documents and designate it as a “Knowledge Base.” For instance, a folder could contain Human Resources documents and policies or marketing-approved Sales assets. We can then facilitate Q&A within this particular Knowledge Base and apply domain-specific prompts, significantly enhancing user experience and productivity. Instead of manually navigating through thousands of documents, users can now simply pose a question to any ‘Knowledge Base’ within their company.
This feature is currently in Beta with a number of our customers.
How it works: Designating a folder as a Knowledge Base
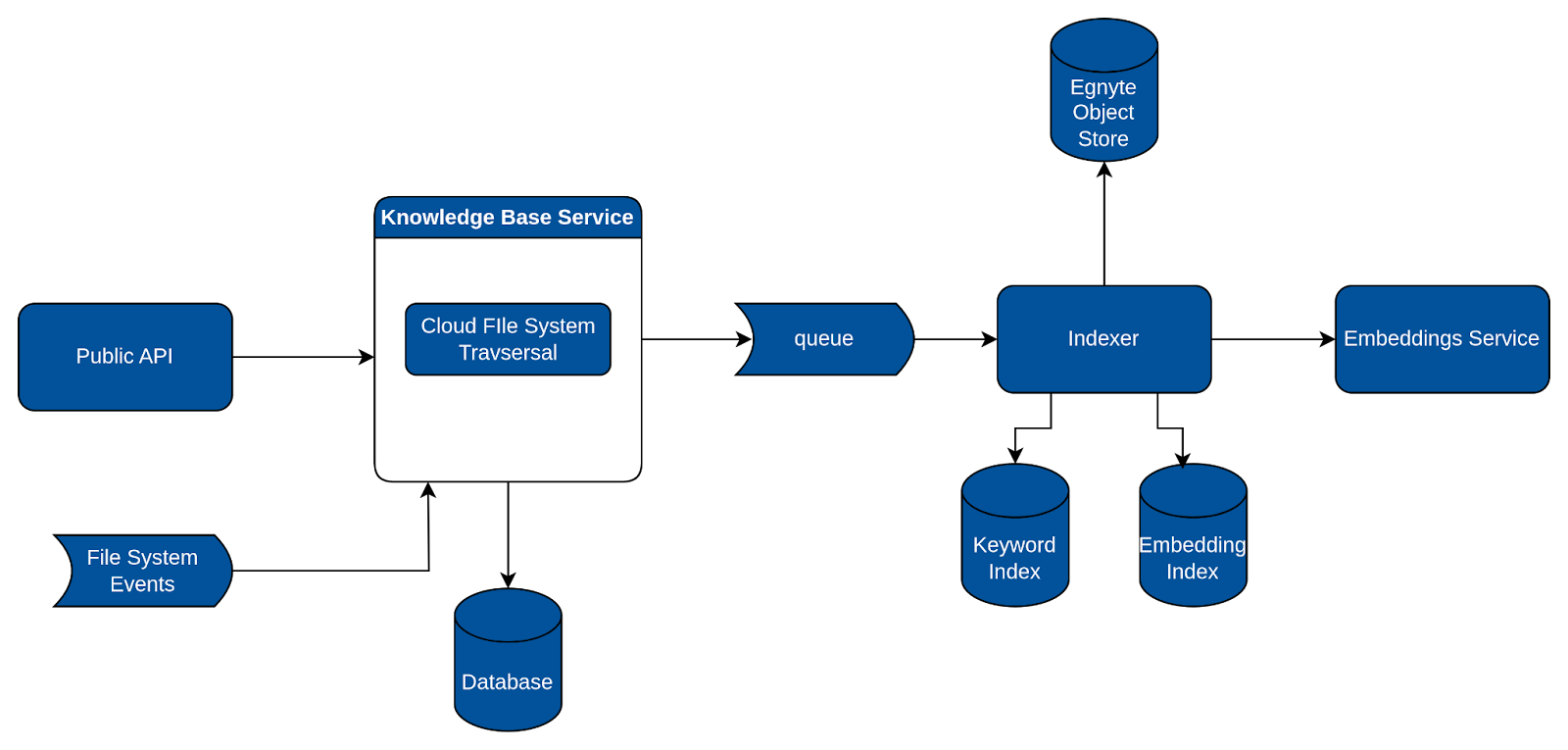
- Once a folder is marked as a Knowledge Base, our backend service springs into action. It saves the Knowledge Base information to a database, traverses the entire folder structure, and publishes events for each file to a queue.
- This is where our 'indexer', another backend component, comes into play. The indexer listens to these events, and for each one, it extracts text from the file, generates vector embeddings, and stores them. We utilize ElasticSearch both as a vector database and keyword index to facilitate this process.
- In addition to this, a folder marked as a Knowledge Base continues to function normally, meaning regular file and folder actions can still occur. For instance, users can add a file to it or move a folder into it. A backend component monitors these events and depending on the action required sends events to the indexer queue.
How it works: Q&A with a Knowledge Base
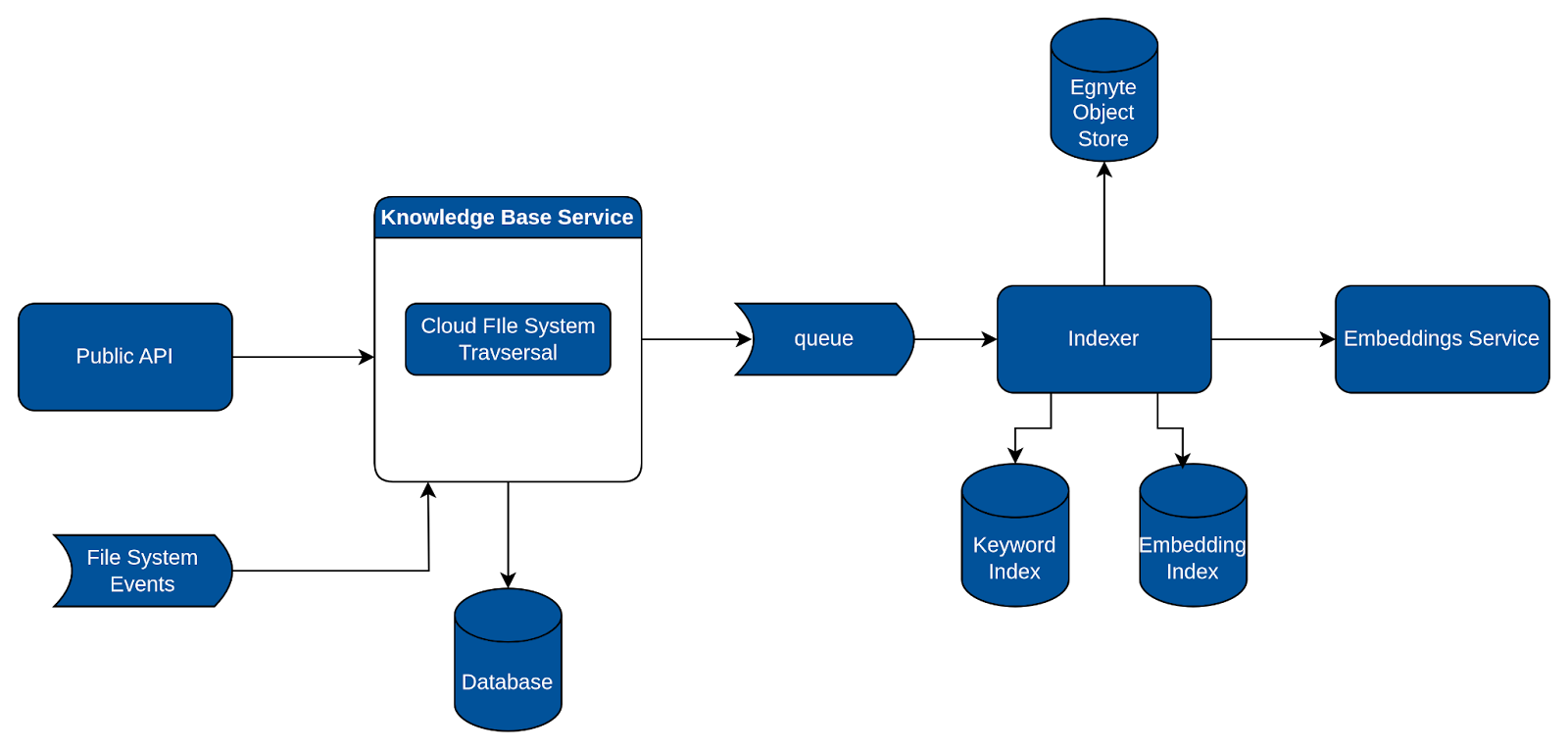
- The user poses a question, which, along with the details of the Knowledge Base, is sent to our search API.
- The search API conducts a hybrid search, including a keyword search on the keyword index and a semantic search on the embeddings index. It then combines and ranks the results. Importantly, it also filters results based on the file and folder permissions of the current user to ensure data security and privacy.
- The Knowledge Base service retrieves the extracted content from the Egnyte Object Store. It then chunks this content according to the offsets from the search API results and forwards it to our AI service.
- The AI service performs an internal re-ranking to ensure the most relevant results are prioritized. It then passes the request to our GenAI models, generating answers complete with citations.
Use Case 4: Helpdesk Q&A
In addition to building Generative AI into our product, in order to support our customers’ business processes, we are also deploying Generative AI across our own business to streamline and improve our marketing, engineering, sales, and customer support operations. Our first major deployment was a Helpdesk chatbot capable of answering questions related to Egnyte. The aim was to enable customers to get instant responses to most of their inquiries, bypassing the need to contact support.
We approach this challenge in the following way:

- We collected and enhanced our ground truth data, which comprised existing Egnyte helpdesk articles.
- We established a pipeline to generate vector embeddings of the ground truth data, storing them in the memory of the helpdesk service. As the data was compact enough to fit into memory, it obviates the need for a persistent vector database.
- Whenever a user poses a question, it is rephrased using an AI model, and a similarity search is conducted on the in-memory vector embeddings.
- The results from the similarity search are re-ranked using an AI model. The top-ranked chunks, along with the rephrased question, are then fed into the AI model to generate the response for the user. This response includes a citation from the relevant helpdesk article.
Closing Thoughts
Egnyte is significantly investing in GenAI across all facets of our business, with many more features under active development. We are constantly testing and tuning different models, which are evolving rapidly. As we do so, data privacy and confidentiality is a paramount concern. To address this, Egnyte has deployed private instances of OpenAI and PaLM LLM models, ensuring customer data is never used to train public models. Our approach to caching or storing customer data adheres strictly to the principles of Egnyte's content storage system. Here, data is stored according to tenant ID, which effectively prevents cross-tenant access. Additionally, we have implemented rigorous permission checks. As a result, a user will not be able to utilize any of the GenAI features for files they do not have access to.
In our upcoming blogs, we will delve deeper into the implementations of some of these GenAI features.