Building a Multi DC Identity Store
As we’re updating and building out our platform, we’re always looking for and developing the best functionality to allow our customers to access and store their data. To enhance access and usability, we geo-balance accounts based on the proximity of the user population to appropriate data centers in the United States, Europe and Asia Pacific. This provides our customers with faster upload and download speeds on large files and better UI performance.
Normally, a customer will create multiple users in one account, and users will sync and share within that account. We have many large, globally distributed customers with independent business units, and we fully support the creation of one account per business unit, where some customers have multiple business units spread across different data centers.Numerous business units and accounts means having multiple logins for some users. This created a usability problem for users because now they’re required to remember the username/password and accounts before logging in. To solve this problem, we introduced two new enterprise features for our customers:
- Email-Based Login: If a user has the same verified email for different accounts, then he can pick which account to login to after authenticating into one of his accounts.
- Account Switching: Once a user signs into one account, he can now easily switch into other account.
To enable these features, we needed to build an identity store that would span across multiple data centers to provide a single view of all accounts and users. We evaluated various technologies to implement this and did proof of concepts with LDAP, MySQL and many more. LDAP identity store worked fine with one to two million objects, but it started having scalability issues, as well as network issues and replication delays, as we integrated additional data centers. This caused us to drop LDAP and started evaluating MySQL.
With MySQL, replication is asynchronous and each server executes operations without waiting for another server to replicate them. It also logs every statement and transmits them to slaves, which works well if a single master accepts the changes from applications and replicates those to slaves. But in our case, multiple data centers would be updating users, and we wanted a multi master-master replication spread across multiple data centers.
We used MySQL circular replication to achieve this as shown in the diagram below. Each data center has PODs to isolate failures, and each pod has its own MySQL to store user/account information. Every app node in the POD will write to its database and also queue a message to a guaranteed delivery table in the same transaction. After the transaction is over, a background thread will deliver the messages to the identity store database or retry them in case the identity store database is not available.
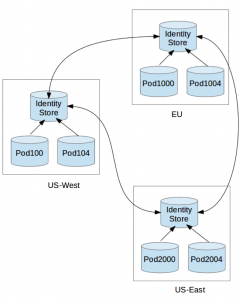
MySQL circular replication then replicates this data across other data centers, and within seconds, we’d have a consistent view in all data centers. Percona 5.6 has multi-threaded replication, which helped us overcome the performance limitations of the regular single-threaded replication. To enable multi-threaded slaves, we did:
mysql > STOP SLAVE;mysql > SET GLOBAL slave_parallel_workers=<workers>mysql > START SLAVE;
To further improve performance in Cross DC replication due to network latency and high load of transactions, we used Replication Compression by enabling: slave_compressed_protocol=1. Enabling this parameter compresses the data transferred over the network to achieve negligible lag under a moderate transaction load.
During this process and testing, there were cases where show slave status was deceiving and looked like replication was working properly (when it wasn’t), and it was not due to network issues between servers. To ensure that replication was up to date, we implemented MASTER_HEARTBEAT_PERIOD that checks for responses from master, and if there was no response for next 300 seconds, slave_net_timeout would restart replication slave_io . In the case when the master was unable to be reached, MASTER_CONNECT_RETRY would retry every 20 seconds.mysql_slave > STOP SLAVE;mysql_slave > CHANGE MASTER MASTER_CONNECT_RETRY=20,MASTER_HEARTBEAT_PERIOD=1mysql_slave > START SLAVE;IN MY.CNF:slave_net_timeout=300ORmysql_slave > SET GLOBAL slave_net_timeout=300;You can check the status of HEARTBEAT:mysql_slave > SHOW STATUS LIKE '%heartbeat%';Below are a few of the results from our sample multi-threaded replication tests during the proof of concept.
Total threadsInsert per threadTotal insertsReplication TimeSlave Compressed ProtocolMulti threaded slaveNo of Schemas5200001000003 minNN152000010000050 secYN152000010000050 secYY110200002000002 minYN210200002000001 minYY2
Circular replication introduces the possibility that two or more servers can replicate concurrent changes to each other, but we had to take into account the few conflicts that could arise for our customers.
- Auto increment keys
- MySQL server time difference
- Use of functions like now()
- Data types like TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
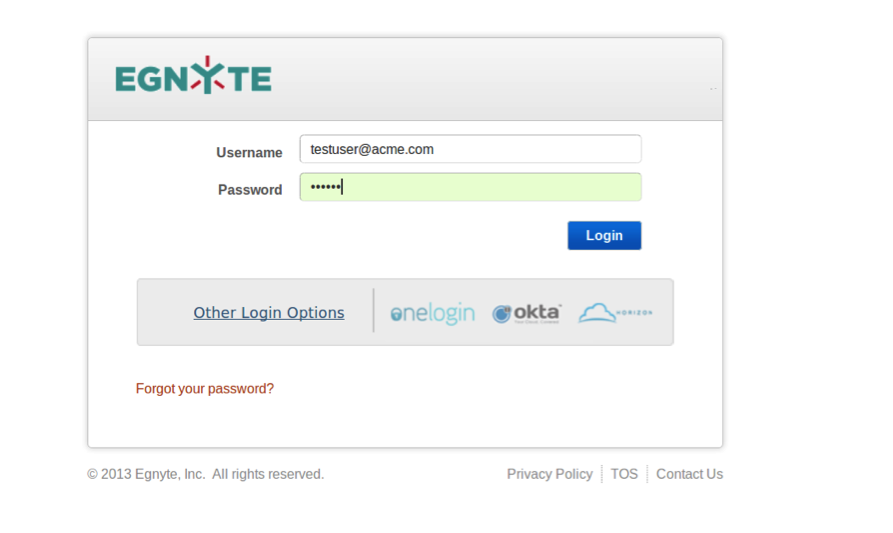
We don't use auto-increment keys in our app so #1 is not a problem. We also ensured all of our servers are in sync with NTP, which resolved #2. We then discovered #3 and #4 after it went live in sleeper mode because our replication checksums for records were different in each data center. We were able to quickly change the applications, hotpatch the code and remigrate data within a week.The migration script was written in such a way that it can be ran multiple times, and if the record between the POD database and identity store database is the same, it will skip or remigrate the record. We also wrote a data consistency checker that will compare records between the POD database and the identity store, which will alert the devops team, if the consistency is broken. To detect circular replication issues, we used the replication checksum and set up a nagios alert to notify the devops team in case the checksums are different or there is a replication delay between data centers.Email-Based Login is already live and available at https://www.egnyte.com/login for all users with verified email addresses. Please contact professional services or support to enable the Account Switching capability (licensed as part of our new Multi-Entity Management feature set) on your accounts. Also, check out a few of the screen shots of the new features.
Email-Based Login

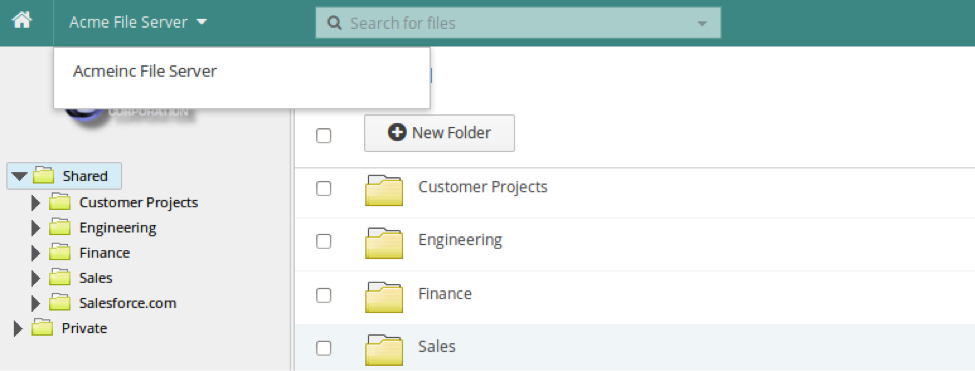
Account Switching
Now it’s possible to switch between accounts with a simple drop-down menu.
*Thanks to Deepak Mehta, Kalpesh Patel, Flavian Castellino, and Manoj Kumar for contributing to this post.