
A Proof-of-Concept for API Caching at Egnyte
As Egnyte’s business and customer base grows, we have an engineering responsibility to provide data quickly and at high availability. In this blog I’ll recap one of those efforts—a proof-of-concept API caching project that serves our large folder listing capabilities and has future applications in other Egnyte services.
Egnyte implements a hierarchical caching strategy—based on various in-memory caching services (Memcached, Redis, in-process)—to cache large listings. To avoid throwing away the full cached listing when a single file changes, we cache on a granular level. Each file and folder metadata has a separate entry, which makes it possible to cache only some of the folder’s content. When a listing is made, we get metadata from the cache first. And if some objects are missing, we fetch them from the backing persistent store.
This solution has worked well, but as more customers make Egnyte part of their day-to-day workflow, the size of those files has continued to grow. Increasingly, we see situations where:
- Part of a large listing is evicted from in-memory caches because of memory pressure, causing us to make frequent and heavy persistent store queries, which substantially increase latency
- For large folders, the time to reconstruct a listing from its pieces adds up, which is very wasteful when folder content is not frequently changing
- Large folders tend to be updated less often than small folders; think archiving, etc.
With that in mind, we took a preemptive step and brought Nginx in as a new caching solution for large listings (folders in excess of tens of thousands of files) as part of the proof of concept. Nginx serves its data from the disk, so we would no longer be under the object size limits for in-memory caches (1 MB default for Memcached), and it could cache these large folder listings in their entirety.
Also, using Nginx would remove a large slice of traffic from in-memory caches, allowing more room to scale and we’d lessen the amount of cache evictions. With millions of folder listings made on a given weekday, this represents a significant decrease in traffic.
Designing the API Cache Flow
We set out with three goals for this project:
- Remove a large portion of traffic from in-memory caches to free them for other operations.
- Provide a just-as-quick alternative to in-memory caches. We save time by not building the listing from small pieces when we use the cached version from Nginx, at the expense of not being able to use in-memory caching.
- Create a repeatable pattern that could be applied to other areas of code loading large, infrequently changing data structures.
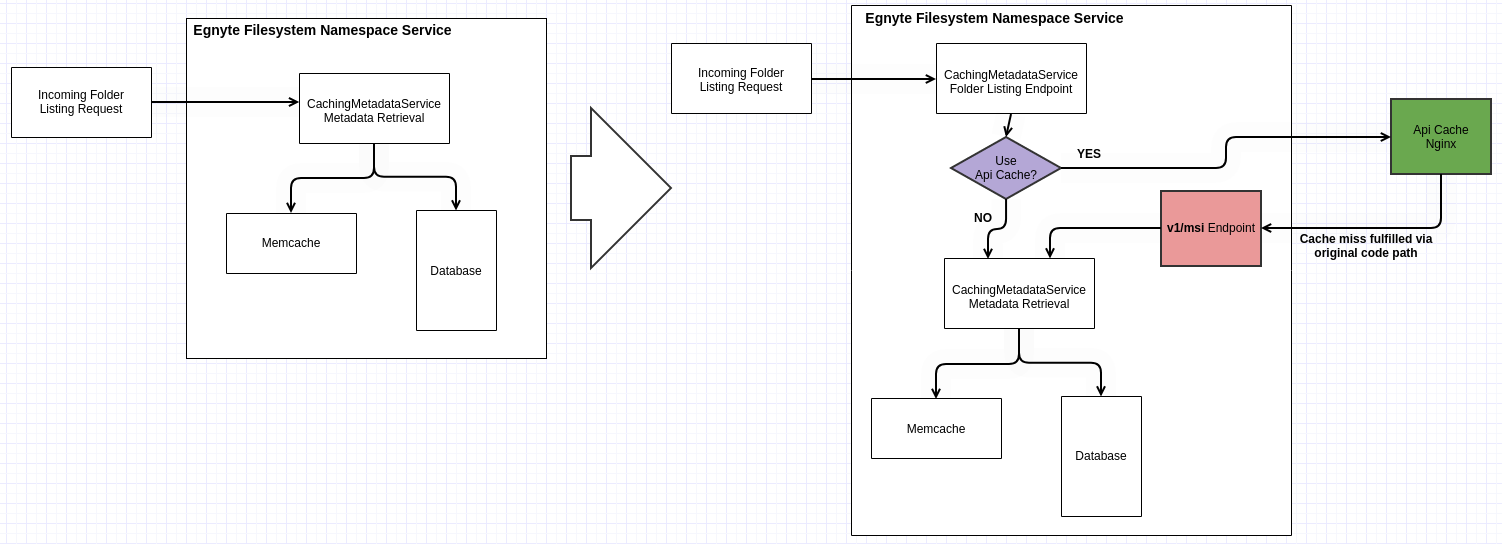
Caching for folder listings is implemented using a read-through caching paradigm, so it was simple to add Nginx as a feature-flagged optional code path. When a folder listing is served by API Cache, the application creates a unique folder version ID (eTag) from the folder path and a folder’s internal “revision_id”.
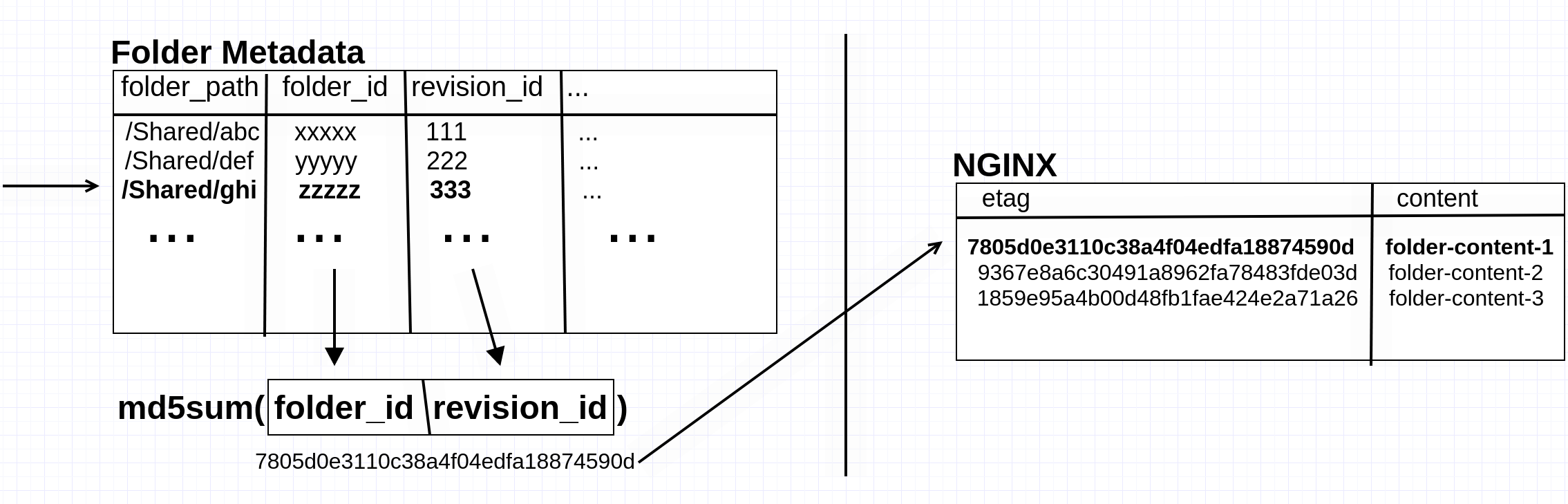
This is a similar identifier to what is used in HTTP caching, and Nginx does its own caching based on this eTag. In the event of a cache miss, Nginx delegates back to the application node via an internal endpoint that serves the listing from the original flow or another feature-flagged path.
Based on previous experience, we set 30,000 files as the cutoff for a “large folder” in this context. Anything larger than that is a candidate for caching via Nginx. In-memory caches still serve smaller listings, so we can continue to reap the benefits of being in-memory.
Getting Nginx Battle-Ready
Since I was refactoring folder listing code, I investigated what other latency improvements could be made in the new code path. I implemented the cache miss as a direct persistent store query rather than delegating to the prior code path. If data for a listing had been evicted from Nginx, it was likely to already be purged from in-memory caches. This was of course A/B tested to validate its superiority over the original for our “large folders.”
Additionally, I did a latency analysis on a single call through our folder listing flow to determine where most of the time is spent. I found that deserialization of the cached data was where we were at our slowest. After reading discourse regarding deserialization via Jackson’s ObjectMapper versus other parsers, I A/B tested a couple different solutions. ObjectMapper turned out to be the best for this case, so I continued to use it.
How Are We Doing?
During performance testing, we bombarded Nginx with requests from the application node at different cache hit/miss densities. We measured throughput and latency at different percentiles as well as at multiple folder listing size ranges. For each feature flag configuration, we were able to measure against the in-memory caching flow where all new features were disabled.
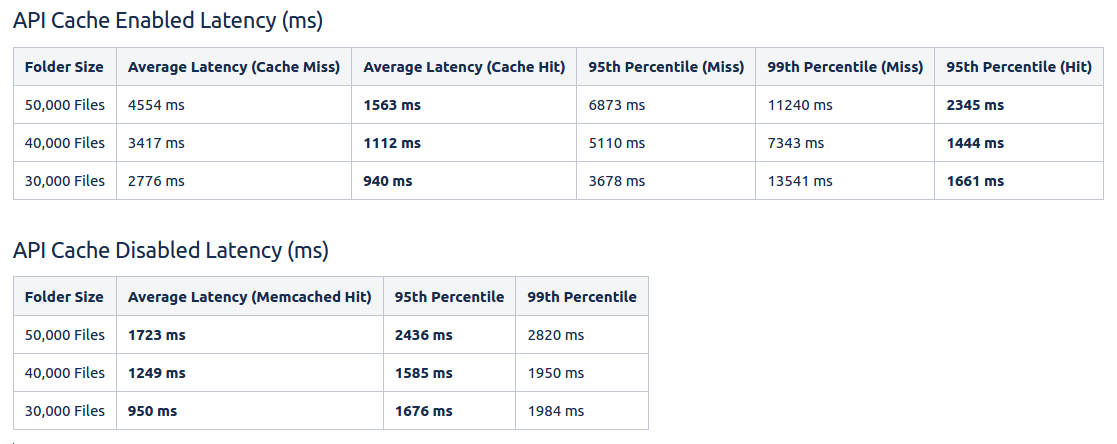
Performance testing indicated that Nginx would be a suitable replacement for large listings, with some caveats. In the case of cache hits as well as on the average, API Cache slightly outperformed in-memory caches in terms of latency. In-memory had a slight advantage in these tests as we forced cache misses by updating a small piece of the listing via a single file upload. This caused requests going through in-memory flow to only fetch a small amount of new data from the persistent store, which artificially decreased in-memory miss latency. Despite this, the testing indicated we are competitive in the average case, plus there was a large value gain in decreasing in-memory caching traffic. We decided to proceed with a slow rollout to production and compare data from real-life use cases.
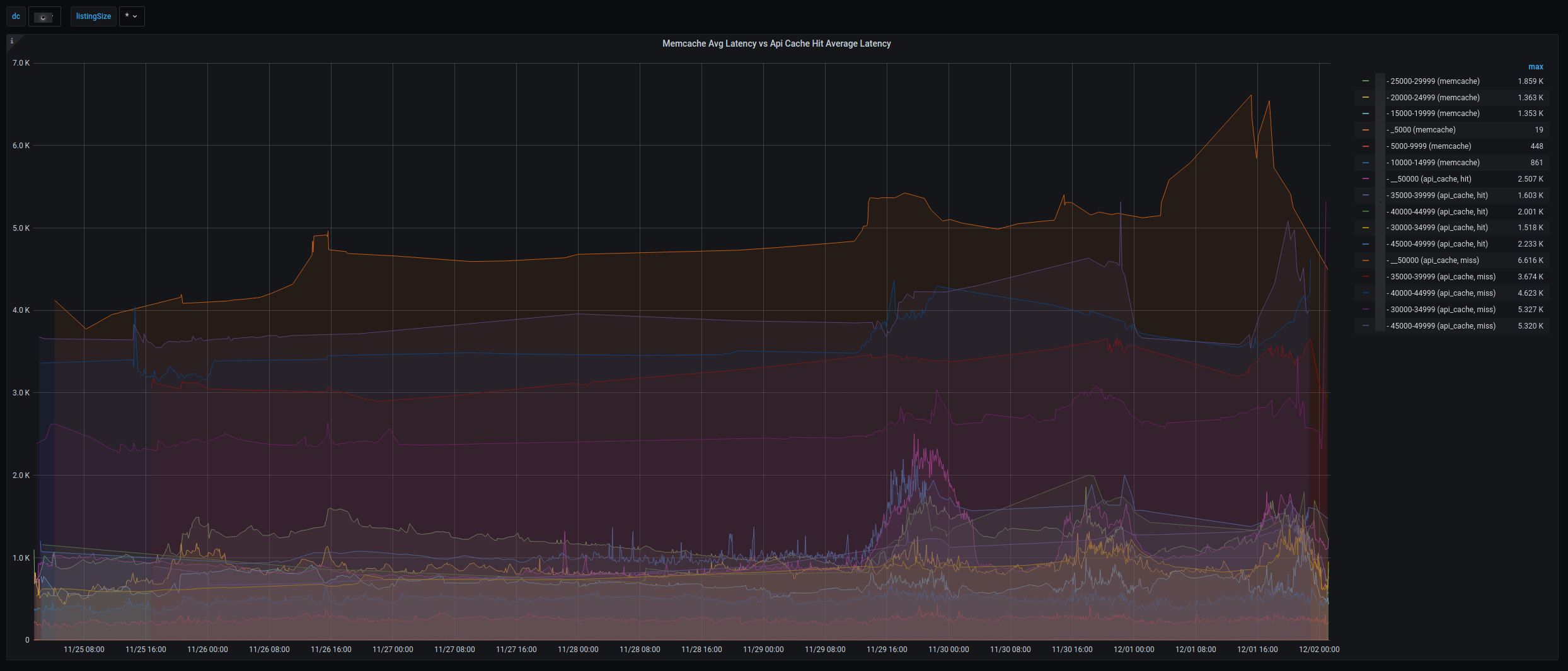
Nginx Out in the Wild (Production)
In its current state, API Cache serves a large portion of traffic in one of our regions and will shortly be rolled out to all remaining production regions. Some highlights of the deployment from production include:
- Performance is in line with the in-memory caching implementation. We determined that the average use case for large folders is a one-to-many relationship of cache misses to cache hits. This ratio is always at least 1:1 and is often much higher, meaning we are gaining a lot of value with each folder served by API Cache.
- Caching pressure has been reduced. Some listings can be greater than 50 MB of just metadata. We save a significant amount of space in-memory and have removed a number of large queries.
- API Cache hits are fast. Each listing served from Nginx (while being served from disk & being in excess of 50MB each in some cases) still averages on the order of <15ms over network.
- Grafana framework will be used for monitoring going forward. During this trial it was important to have metric insight. As we do in many other areas, we leverage OpenTSDB + Grafana for this. An abundance of newly added application metrics help me keep on top of performance as I monitor day to day.
What Does the Future Look Like?
Going forward, we hope to apply the general idea of this API Caching project to other areas of the platform. My changes were made with a general application in mind, and with minor edits, these changes can be replicated in other areas to reap the benefits of Nginx caching. Only small changes to application code need to be made to configure Nginx to cache different objects and delegate to other cache miss fulfillment endpoints.
On a personal note, this project brings to a close my third year as a Software Engineer at Egnyte. I’ve progressed in my role at Egnyte in a number of ways, which has helped push my own work forward. With my work on this project, I have grown more autonomous and self-reliant in terms of coordinating work with other teams and making sure that any blockers for forward progress are handled quickly. I’ve had to be responsible for assessing the viability of new technologies and figuring out how they will affect my implementation. I’ve had to overcome issues with deployments, both on a configuration and performance level.
I’m looking forward to more growth with Egnyte. If you're interested in joining our team, check out the Egnyte careers page.






