From Paper to Protected With Optical Character Recognition
Going digital
For many organizations, the transition to paperless systems is fraught with operational challenges. The difficulty is not so much with the deployment and adoption of digital tools, but rather with converting piles of paper into usable data. The first step in this process is high-volume document scanning; turning the physical stuff digital. Next, it’s time to make sense of the image captures. Because unstructured data analysis is still in its infancy, businesses must convert scanned images, charts, forms, etc. into searchable text before the data within them can be put to good use. This is where OCR (optical character recognition) comes into play.
Before OCR services became readily available in 2000, people were hired to convert scans/raster images into editable data. While data entry is an essential part of business modernization, doing so solely by hand is costly, time consuming, and runs the risk of human error.
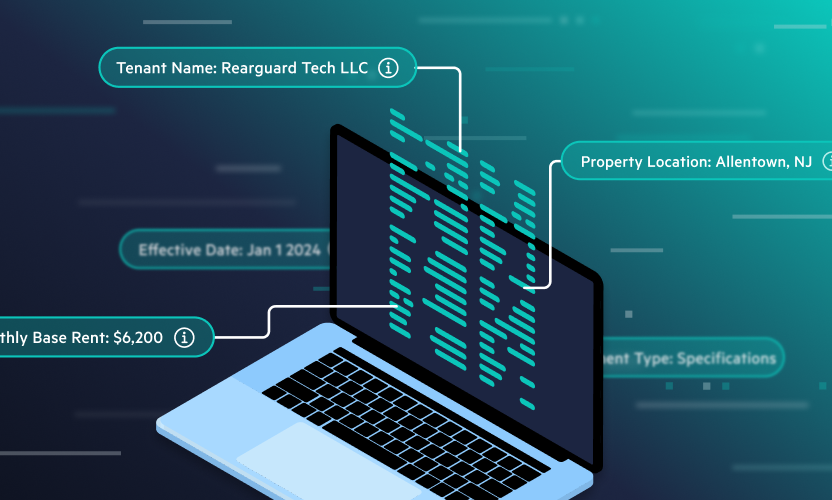
OCR does so much more than make manual data entry a thing of the past. It helps ensure data integrity by increasing accuracy, which is vital for insights-driven organizations that rely on data for everyday operations. OCR makes image-based files searchable by adding an essential layer of text, improving overall data visibility and protection capabilities for businesses that know how to wield it.
Here’s how:
- Paper gets scanned
- OCR uses pattern recognition techniques to extract text, be it typed, handwritten, or printed, from digitized documents and convert it into searchable/editable data.
- As part of a content governance solution, data classification software takes the extracted data and analyzes it to determine what is relevant, redundant, important, sensitive, etc…
When added to data classification software, OCR can reveal the hidden value in legacy data. What once took days can be done in seconds and with incredible accuracy; leaving businesses with new sets of useable data that are easier to manage and protect.
How Egnyte uses OCR
Egnyte offers document capture tools that enable text recognition in a variety of file formats, including scanned images, PDFs, and forms completed by hand. Our content governance solution incorporates advanced classification technology like OCR to make sense of the information within scanned documents.
Check out our short video on OCR to learn more.