
Applying 80-20 Rule to SRE
The Pareto principle states that 80% of results can come from 20% of efforts. I work on Egnyte’s Infrastructure team and the fact that this is a small group means we walk a fine line between keeping the system humming and making the necessary platform enhancements to handle the next growth spurt. The Pareto principle guides us to pick the right battles and by applying 20% of proactive efforts on the right problems, we’re able to prevent 80% of reactive problems.At the core of Egnyte Connect service is a Distributed File System and as with any other File System, the most common user operations include listing folders and uploading/downloading files. Our monitoring tools indicate that as the adoption of newer Desktop App clients increases, the average list folder performance went up from 50 milliseconds(ms) to 70ms in some data center zones (we call them Pods). In the past few months, we’ve made scalability enhancements to fix this and to also handle the next growth spurt, without adding much additional hardware. Now, 70ms is not a bad response time for list folder API, but if it’s called 100-200 million times, then that number can go up quickly. Even a 10ms improvement in performance can save 1-2 billion ms a day. How do you optimize something that is already fast? Well, sometimes ideas cross-pollinate when working on unrelated problems. Some relevant scalability enhancements we worked on include:
Reduction of response size
We have a REST API for listing files and folders with detailed responses to support different use cases. One day, while working on a specific use case, I realized that some of the cases require long, detailed responses while others don't. While looking at call frequency, I decided to trim one API response for a few high-frequency user-agents. I worked with the appropriate teams to change the implementation and create a reduced response size for these high-frequency user-agents. We left the other use cases be. Doing this had an interesting outcome:
- Trimming the response also reduced cache/database calls to load some compute-expensive fields. We saw around 100K fewer queries per minute in some of the Pods. Below is a screenshot from QA showing the nosedive in one of the queries.
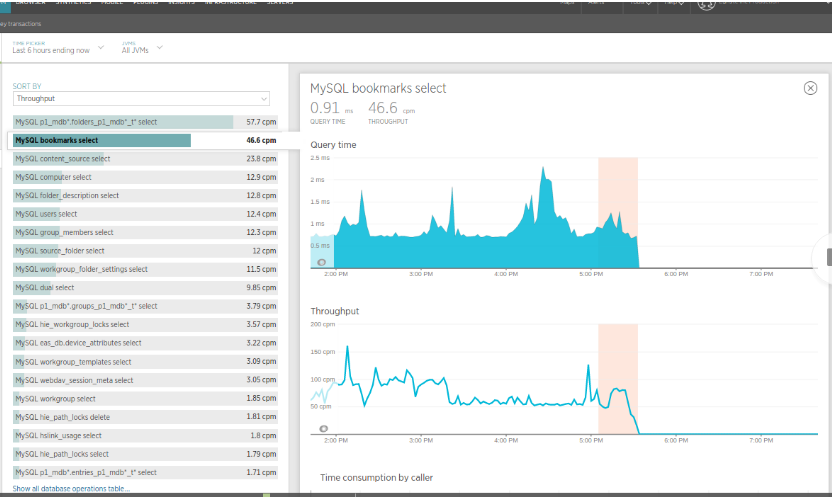
2. During high load times, some network saturation was evident by intermittent cache connection timeout, and as the response size decreased, the saturation disappeared.This small performance change itself lead to a 10ms performance improvement per API call.
Primary Key Change in File System tables
While looking at our APM solution, we found some instances of list folder/files queries that were taking 10-20 seconds for large folders:select * from files where customer_id=? And file_id in (?,?,?,?,?.... 1000 times) select * from versions where customer_id=? And version_id in (?,?,?,?,?.... 1000 times) I was puzzled. The Primary Key on files table is (file_id, customer_id), on versions table is (version_id, customer_id) and the Primary Key access shouldn’t be this slow. A few days later, when we were colocating customer data in a search index shared to improve performance, I realized that the large list folder query may also be slow because the files of a folder are distributed all over the disk due to primary key distribution on file_id. I also realized that customer_id was the second column in order, so a query like,Select * from files where customer_id=? and file_id=? is faster for one record lookup but slower for 10K record lookups. This is because you have to read a lot of random blocks from disk, even when accessing by primary key. As list folder is the most common use case, it makes sense to colocate file metadata of a folder together on disk, in database tables. Therefore, we decided to make this query faster at the expense of making some other lesser-used cases a bit slower. We decided to change queries to include new fields and primary keys on
- Folder table from (folder_id,customer_id) to (customer_id,folder_id)
- File table (file_id,customer_id) to (customer_id,folder_id,file_id)
- Versions table (version_id,customer_id) to (customer_id,file_id,version_id)
As we are dealing with 10s of billions of records, a change like this can have a massive impact, requiring extensive performance testing over a month. We changed the primary keys a few databases at a time, under a feature flag that would enable new queries Pod by Pod. The entire primary key update process took over a month as we had to keep the current system humming. As expected, we got a 50% performance improvement on some of the heavily used queries as shown below.
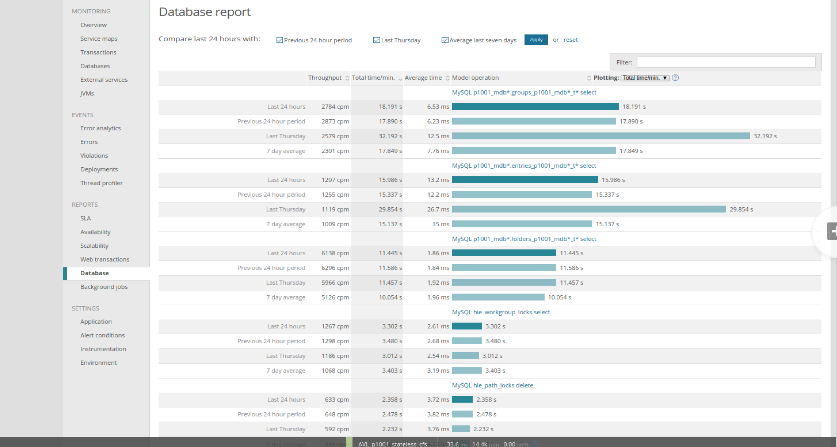
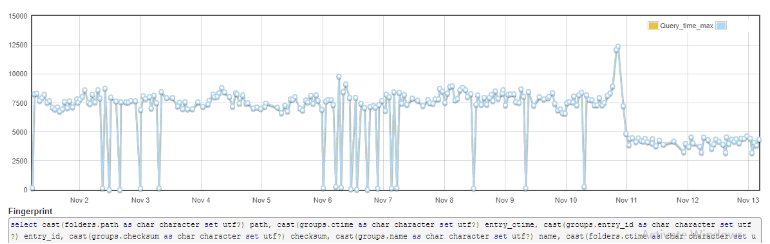
This change resulted in another positive outcome; all customer metadata was now collocated together in tables because customer_id was the first column on core tables. Also, full snapshot times for large workgroups was reduced to half, as shown by the dip in the graph below around Nov 11.
Check files first and then folder
One of our principal engineers was diagnosing an unrelated issue when he noticed that two of the APIs were called a lot more than others - 100's of times more. As such, it was worthwhile to investigate the code - are we optimized as much as possible in this flow? Even a small gain per call would be significant. While investigating, he noticed something strange. For listing files of a folder, we are making some repeated queries on the folders table that returned no records. Our first reaction was to add a NULL_MARKER in our cache for nonexisting paths, but upon doing a deeper analysis, we found that a helper API is written suboptimally to make one use case simply was being reused by a high-frequency use case. The API allows you to get details about a file, folder or version using a path like /pubapi/fsi/${UUID}. Although this makes life easy for this use case caller, the server code has no idea whether a user is asking for a folder, a file or a version. Therefore, it’s forced to do a fallback by first checking if it’s a folder, then file and lastly, a version. As the other high-frequency user agent was calling this API 100s of millions of times a day, we were getting close to 100M cache/database queries returning no results. The fix was simple. We know that for most customers, folder to file ratio is 1:10. We reversed the order of fallback to the first check if the UUID is a file and then a folder. This gave us 10% improvement, but when applied to an API that’s called 100s of millions of time a day, the impact is massive. We now have additional resource capacity on cache/database left for real usage. Below is a screenshot of one of the Pods showing the dip, the in-query count that gave us immediate relief. We will now work in future sprints to provide a new optimal API for this specific high-frequency user agent.

As a side effect of these improvements, the system became faster and we found that the throughput increased by 15% without adding many new resources.Taking the time to focus on the few tasks that can result in maximum gain is critical for improving complex systems like Egnyte Connect. Without this focus, teams can quickly get bogged down in the myriad details of the day-to-day activity.






