
The Journey to 7X Search Performance Improvement
Egnyte is used by our customers as a unified platform to govern and secure billions of files everywhere. As the amount of data stored is huge, customers want to search their dataset by metadata attributes like name, user, comments, custom metadata, and many more, including the possibility to find files by content keywords. Taking all of that into consideration, we needed to provide a solution that is able to find relevant content in a fast and accurate way. It also had to be flexible enough to allow searching by various criteria.
We introduced Elasticsearch to power the search solution around 2014, and over the years, it served its purpose well. However, as Egnyte grew, the data stored in various search clusters became quite large. As a result, the search response time increased gradually from sub-seconds to as high as 14 seconds on some of the larger datasets. This blog post is about the journey we took to bring the average search response time to be under 2 seconds.
We conducted several in production behind feature flags to reach the 7x search performance improvement. The POCs at a high level can be grouped into these topics:
- Cluster upgrade
- Removing unused functionality
- Reducing the number of deleted documents
- Hardware upgrade, and
- Indexing improvements
Change POCs to experiments? It feels like it wasn't completed but these are actual projects we completed and took live. Some of these we didn't complete as part of the POC because we found them not effective or rather we hit our performance targets.
Cluster upgrade
We have been running Elasticsearch 2.x for the last 4 years, and it was pretty stable. The first thing we did was to upgrade the Elasticsearch cluster to the latest 7.x version to take advantage of the latest performance optimizations and tools. Elastic search 7.x is not compatible with the index created in 2.x, so it was necessary to reindex the entire data set. Knowing that we had to do it anyway, we decided to do a few other tweaks along with the reindexing project.
Cluster split
We started Egnyte search infrastructure with one cluster per region. This large infrastructure made rapid performance prototyping difficult. The isolation level was also high. This meant it difficult to introduce any big infrastructure or design changes as it was time-consuming and impacted a large number of customers. To alleviate that problem, we divided each cluster into 4 clusters per region. These smaller clusters also allowed us to reduce our full cluster backup times.
Index Split
In old clusters, the indices were becoming large, and multiple large customers hosted on the same index caused noisy neighbor issues. We split big indices into smaller indices and provisioned separate indices for some of the larger customers.
Content reduction
We used to index up to 1MB of file content. However, we ran an experiment to find out the optimal size of the content without reducing the quality of the search results. We started with the first 1MB of the document content being indexed and kept reducing the size and measured search quality. We, then, ran a comparison where we got the first 10000 tokens with 100KB and 50KB documents. We concluded that the first 50KB of the document content gave us the same quality for search. It was a great finding for us, as it reduced data size by 30% and also reduced the document size leading to faster reads from the disk.
Summary
Doing the cluster upgrade, splitting into multiple clusters, splitting into smaller indices, and reducing content size gave us around 30% improvement in search response time. Most of this was achieved due to data model changes. Some of these were more helpful than others, and with the upgrade, we got better profiling output and tools to visualize query profiles.
Removing unused functionalities
However, we were still unsatisfied with the results, and we started exploring more POCs listed below.
Trigram removal
To do a fuzzy search, we were generating trigrams on file and folder names during indexing. We found that the trigrams were generating a huge token set and we were already making a match and prefix query on the filename and folder name. From our operational metrics and A/B testing, we found that removing trigrams did not reduce search quality and improved the search response time. Based on that, we decided to abandon trigrams and support only exact and prefix matches. Our observations were based on replaying a week’s worth of production queries that produced the stats shown below:

*Index of the first mismatch: Comparing results from both queries, the index where the first mismatch of document occurred between results in the two approaches.
Term query removal
This change was around the way we were doing an exact term match on file and folder name. We were also doing a match query on analyzed tokens. Tests showed that the exact term match was not required as the match query on analyzed tokens would also match documents that would additionally match with the term query. This analysis helped us eliminate the term query.
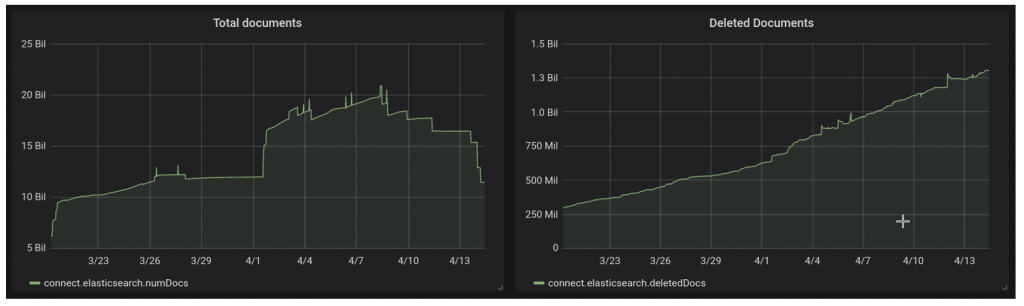
Reducing deleted documents
A vast majority of the documents managed by Egnyte represent active files. Each document has its own lifecycle and it is mutated many times over its lifespan. Once a file is added, it may be moved, renamed, annotated with comments or custom metadata, and may finally be moved to the trash where it will eventually get purged. This churn in the active file system causes a lot of index updates which in Elasticsearch world, results in the addition of a new document along with the deletion of the old document. Additionally, to support search by path elements, we denormalize the full file path within each document in the index. As a result, when moves are performed on Egnyte file system, they can cause millions of documents to be updated to reflect the new path. This lifecycle, again causes a lot of deleted documents within Elasticsearch.We took several initiatives to reduce the number of deleted documents. Some of them are described below.
Store content as a child document
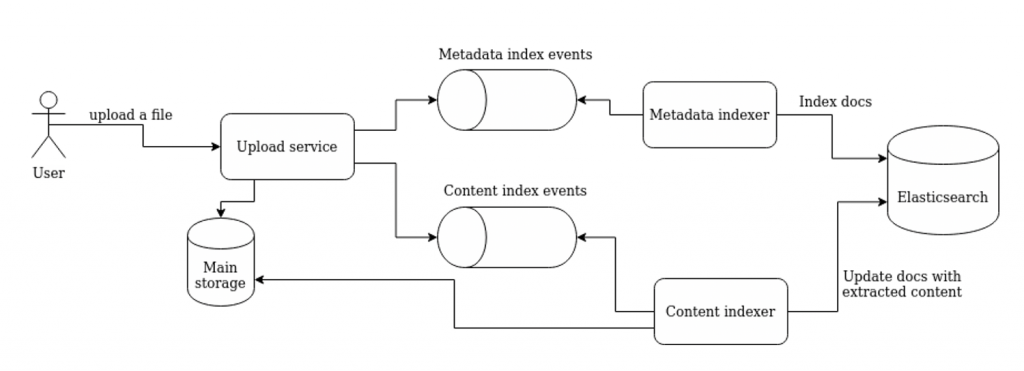
Egnyte’s search system has a separate pipeline to index the content of a document. As extracting content from uploaded files can take some time, we perform content extraction independently of indexing the metadata of the file (such as file attributes). This allows our users to start searching by file metadata well ahead of the content index becoming ready. As an unwarranted side effect of this parallel processing, content indexing creates deleted documents in the Elasticsearch cluster as we update the content field of already indexed documents. We did a POC to see if we could store the content as a nested child document so that content indexing will not update the document. However, performance tests on the index with parent-child documents showed that search time increased with an accompanying increase in disk space as well. Hence we dropped this idea.
Staging index
Some more research led us to the fact that for the smaller indices, segment merges were happening frequently. Similar to how a JVM uses young and old generations, we came up with the idea of a staging index. The idea was to introduce a second index adjacent to the main index, that will store documents temporarily before they are updated with content. Thanks to this, we don’t update documents in the main index but insert a completed one. As a result, we decreased the number of deleted documents in the main index.
Hardware upgrade
Giving more RAM
In Egnyte’s Elasticsearch clusters, we could have many customers assigned to one index and many indexes are stored on one physical node. Searches by different customers can cause filesystem cache thrashing and also high read activity on the disk subsystems. We decided to increase the memory from 30GB to 200GB on each data node to allow more data to remain in the cache and, therefore, less amount of paging. It resulted in a big improvement in search response times.
However, increasing RAM on all data nodes was expensive and was not a scalable solution as our search data grows daily, and we store 2-3TB of indexes on each data node. The 200GB of RAM would, at some point, reach its peak and performance would again start degrading. Knowing this, we decided to experiment with the storage itself.
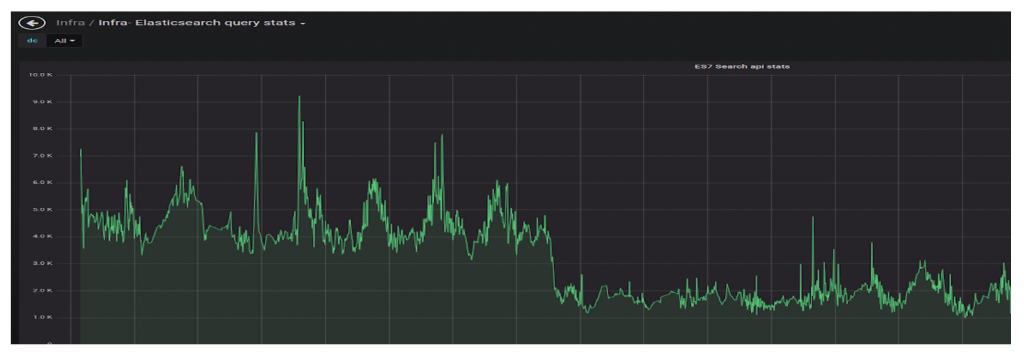
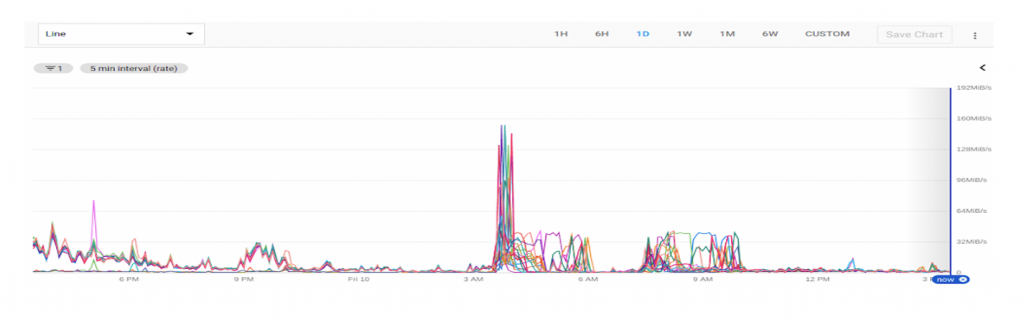
High IO Usage
We noticed high IO usage on our data nodes, as you can see here:
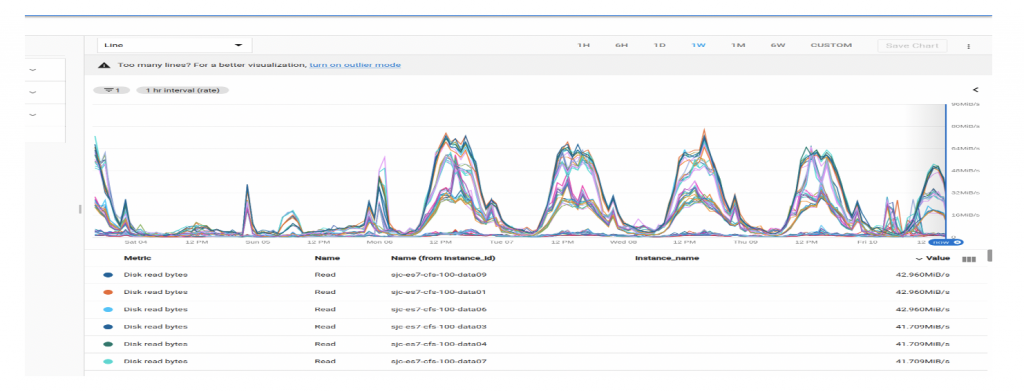
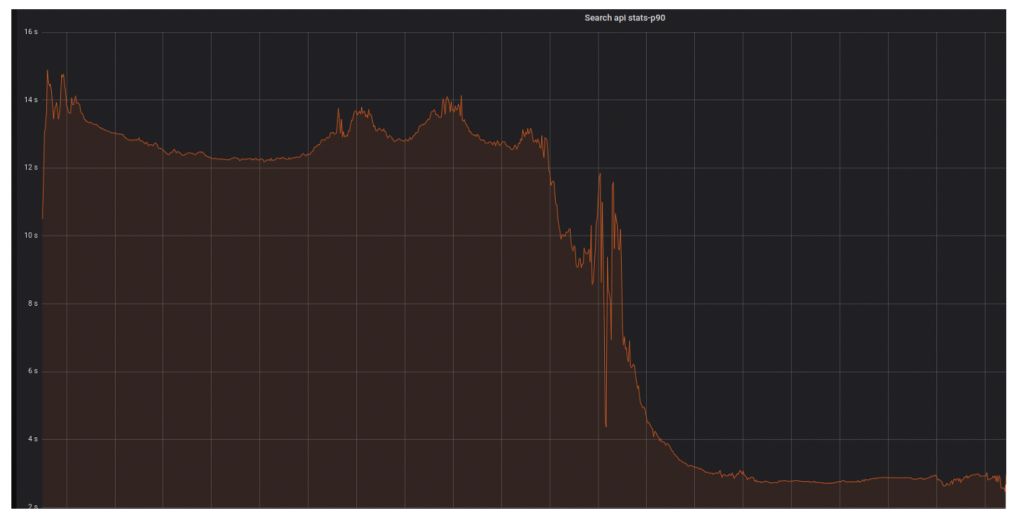
It was an indicator that indexing and search are heavily I/O dependent. We moved one cluster on SSD and it was an Aha! moment in our journey. The I/O usage dropped and it made a huge impact on search and indexing throughput. After that, we decided to move all of our clusters to SSD. Migrating to faster disks was of course beneficial and came at a higher cost.IO Usage improvement:
Search Response time Improvement:
Thanks to SSD, we were also able to introduce the sorting feature in the UI, allowing users to sort search results using the name, size, and modified date.

We are doing a few more POCs to see if we can separate data into hot/cold and host the hot data on SSD and cold data on HDD to reduce the costs while providing optimal search experience.
Indexing improvements
Updating by ID
In the case of indexing, we found that a lot of time was spent to find target documents to update. The problem was that we were using “update by query” for many document update actions due to legacy reasons. The “update by query” was generating an artificial search load on the cluster and also caused cache thrashing. The solution was to use “update by ID” for frequent actions. To achieve this, we changed our event logging to log additional metadata and migrated actions to use “update by id” behind a feature flag. Thanks to this, we were able to cut the execution time of indexing actions on average by 50%. This effect was flattened a bit after migrating to SSD, but nevertheless, we could clearly see that on a bigger data set as our using ids to update documents gives better results than using paths.Using “Update by path”:
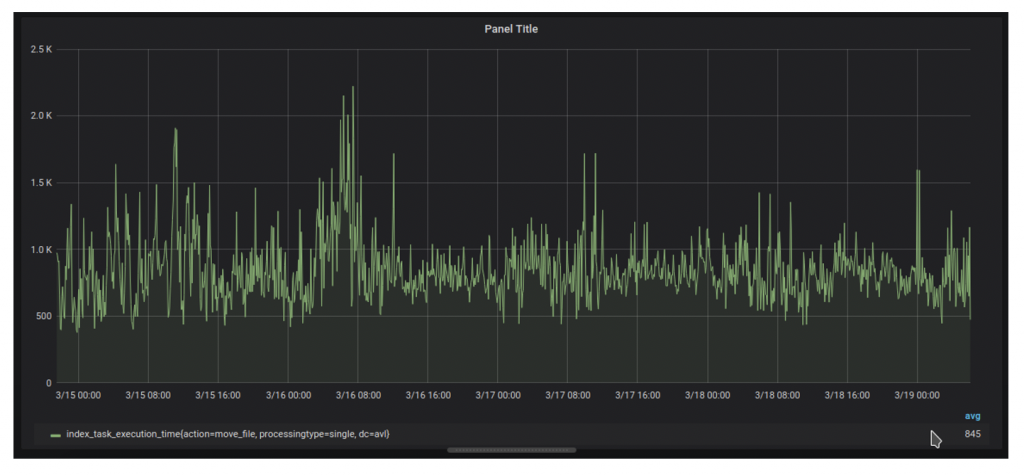
Using “Update by ID”:
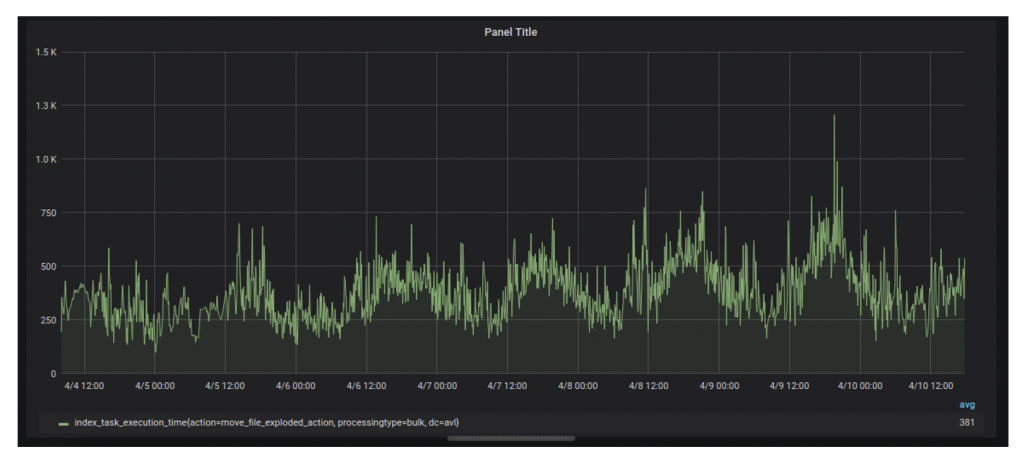
The above examples show that we were able to reduce indexing time performance by 50%.
Final thoughts
Our journey had many frustrating moments where POCs didn’t perform as expected and many joyful moments where small changes made big improvements. The lesson to learn here is that, when faced with a daunting task, do not give up. Keep nibbling at it every release and you will, at some point, break through the barrier. We recommend doing smaller POCs behind feature flags in production and use a data-driven approach to make decisions about them. This approach saves time invested in implementing a large solution that may not perform and also reduces frustration. In the end, our journey can be described using the following picture:

The successful search performance improvement journey was the combined effort of the entire search team — Deepak Mehta, Szymon Miezal, Hubert Poznanski, Kalpesh Patel and Amrit Jassal
Photo by Markus Winkler on Unsplash






