
How Egnyte Handles API Mocking: A Mirage.js Case Study
Mocking API requests for local development purposes or tests can be really cumbersome for frontend developers. The payload can be very large, identifiers of related entities must match, and besides that, sometimes we would like to get a completely different response depending on a use case.
How do you avoid the extra work and avoid ending up with a mass of a half-duplicated code? At Egnyte, we cope with this challenge by using Mirage.js library.
In this blog post, we’ll describe how we do API mocking within Secure & Govern, Egnyte’s smart content governance solution that notifies users about any potential exposures of sensitive information in real-time, allowing them to take action to prevent costly data breaches.
What is Mirage.js and How Does Egnyte Use it?
Mirage.js is an API mocking library that works in the browser. In essence, it intercepts any XMLHttpRequest or fetch requests your JavaScript app makes and lets you mock the response.
The essential concept that distinguishes Mirage from other API mocking tools is the fact that it operates on an in-memory database. This database stores all of the Mirage’s state, which can be accessed or modified by using route handlers. Thanks to that, the state of an entire app stays consistent—the same API endpoints may respond with different data depending on previous interactions. Actually, it behaves like the real backend!
This setup is being used in several use cases in our project.
Local Development
We use Mirage as the default way to develop a frontend locally, when no backend is provided. Its initial dataset is configured using seed functions that can be extended or edited during the development. Each response can be temporarily modified to handle specific UI behaviors, e.g., individual status codes. The important part: new features can be developed independently of the backend team when the proper API contract is set upfront.
Cypress and Visual Regression Tests
To avoid intercepting every single request using static fixtures in Cypress, we use the Mirage server in the background. It intercepts all requests that the frontend app makes. But this creates a challenge of populating the database with an appropriate dataset depending on the test case. To handle that, we created a custom mechanism called scenarios that we use for filling the database with predefined data for specific features.
It also applies to visual regression testing, which is Cypress-based.
Unit Tests
Using Mirage in unit tests allows us to check whether the expected request is sent, as well as whether it contains the right payload. The database is populated using the aforementioned scenarios. Once the requests respond with meaningful data, we also check if derived data are properly saved in the Redux store.
How Do We Work With Mirage.js?
In order to work effectively with Mirage.js library, it’s necessary to get familiar with core concepts and mechanisms on which it is built. In our project, we mostly use them exactly as they are described in the documentation. However, some of these concepts and mechanisms had to be slightly altered to meet our needs. In this section, we’ll describe how we work with Mirage from an engineering perspective, including core mechanisms, code examples, and managing limitations.
Server
This is the entry point for starting up the Mirage server with the given configuration. All the mechanisms described later in this article are combined at the server level.
Route handlers
They define how particular requests are being intercepted by the Mirage server. To handle a single request you need to know its HTTP method and match the URL. Here is an example of a route handler for listing folders:
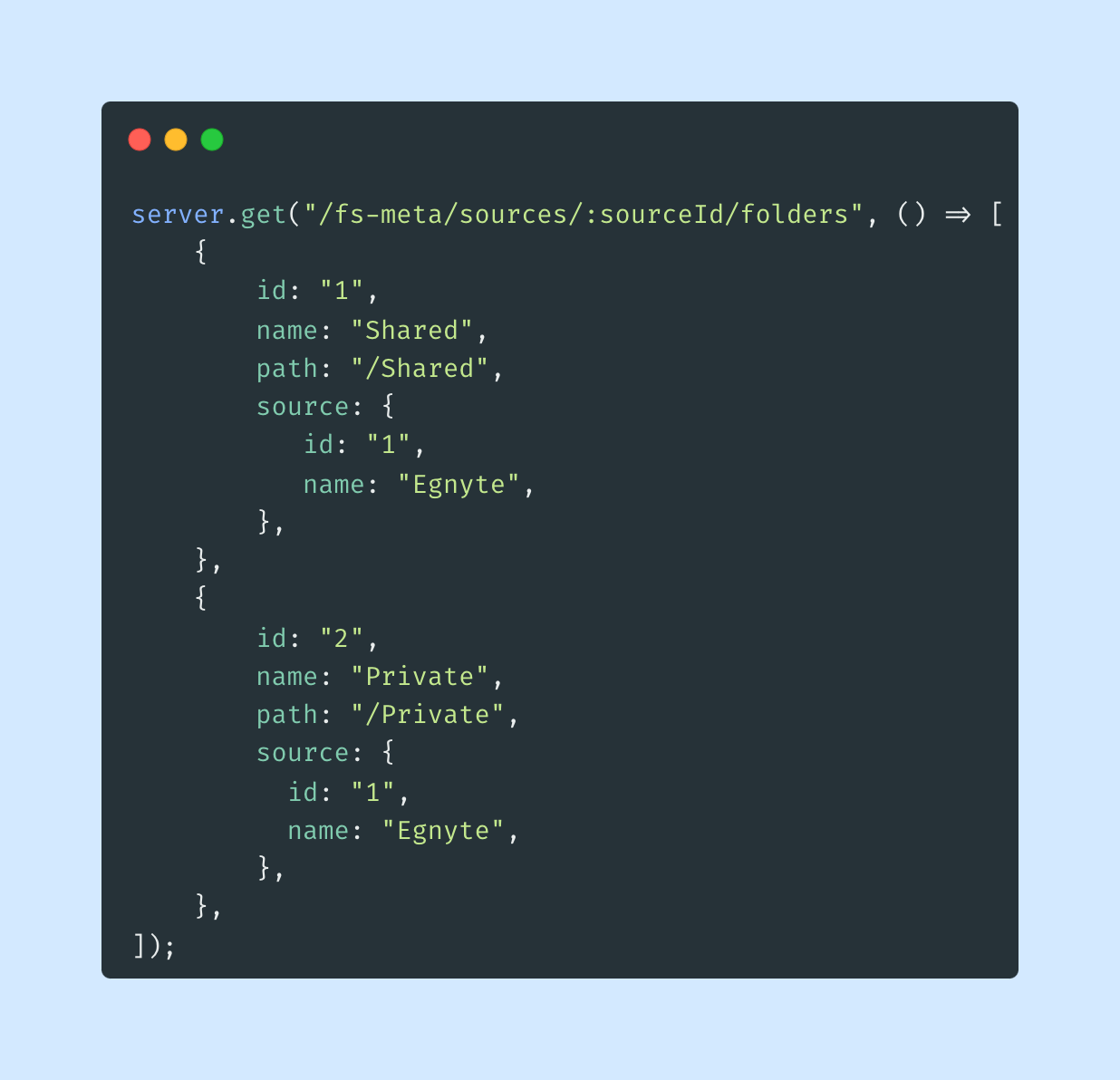
The biggest drawback of this example is the fact that the list of folders is completely static. It returns the same two hard-coded folders every time it runs, no matter what source it refers to. Also, the above endpoint may take an optional parentId query param that points to the parent folder. It is not handled as well.
To make this route handler dynamic, we need to somehow access the data from the in-memory database. To do so, we need to get familiar with other concepts.
Models
Models are classes that define what type of entries are going to be kept in the database. Their declarations also have information about relationships with other models, which unleashes the power of leveraging the ORM. Unfortunately, they don’t define what properties the model can take (at least in the plain JavaScript syntax).
In our project, every model has a separate file for its definition. A simplified model definition for a folder entry looks like this:

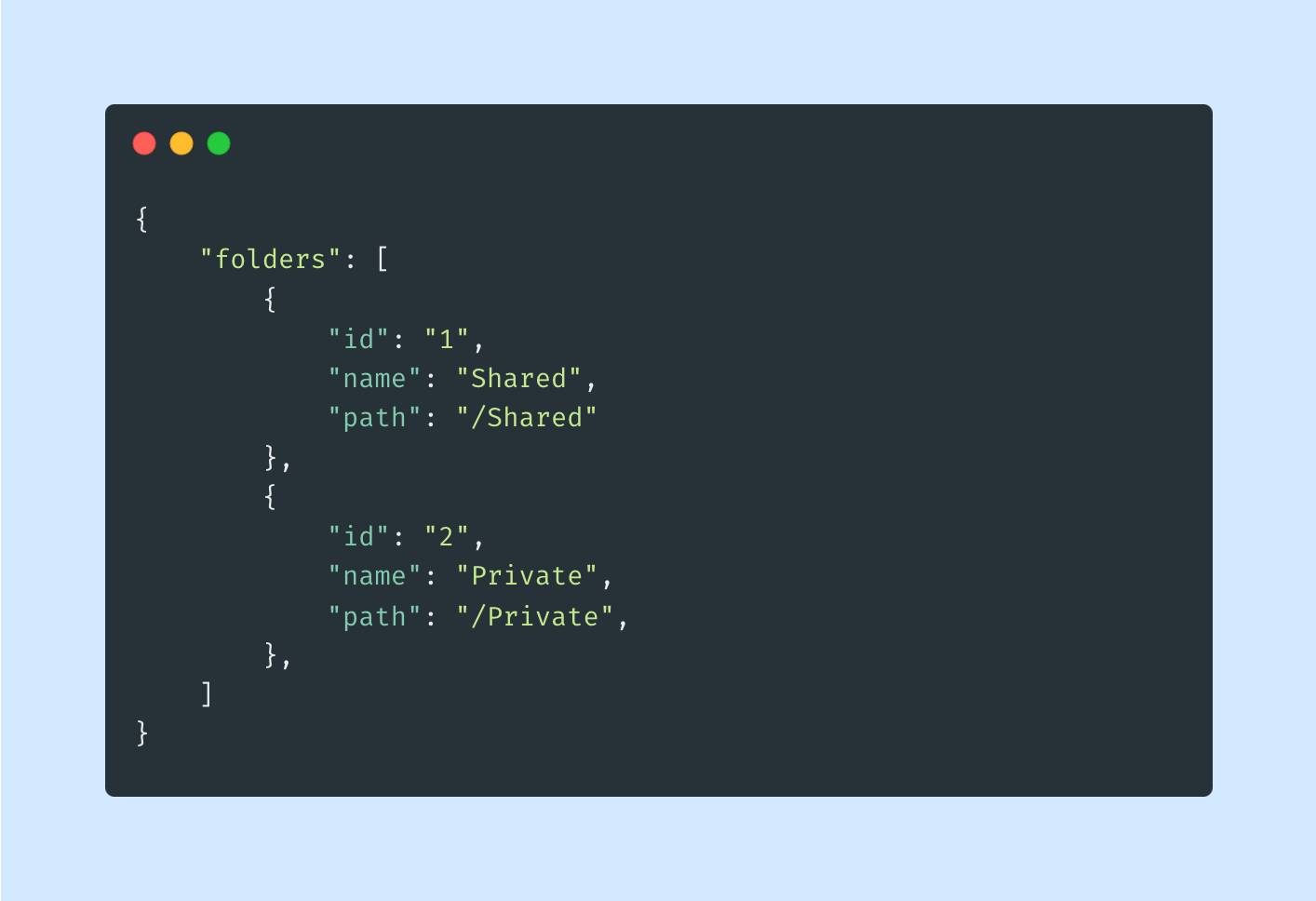
Having such folder model defined, we are allowed to create folder’s entries:

The above snippet will create two folders and store them under folders
collection in the database:
Note1: Mirage automatically pluralizes model names to collection keys
Note 2: By default, Mirage uses autoincrementing numbers starting with 1 as IDs for records
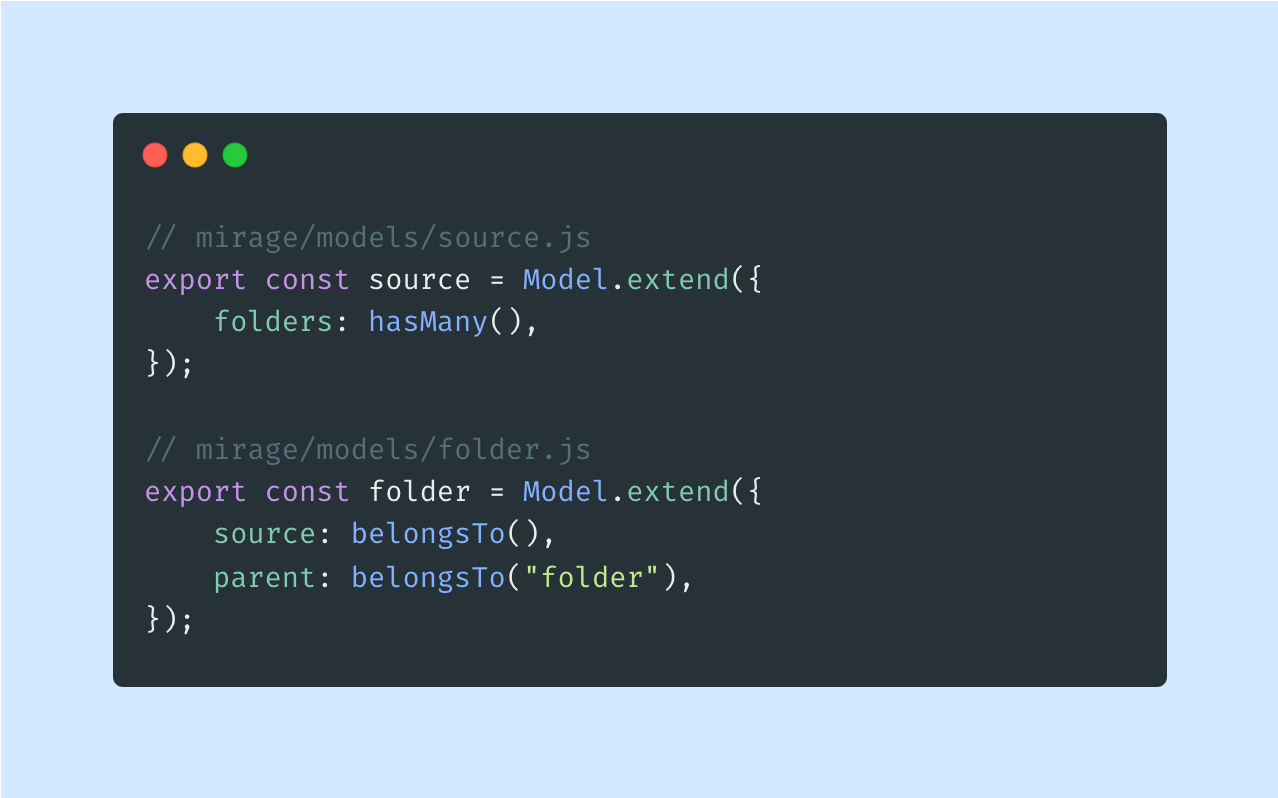
Relationships
Having base models set on isn’t enough to correlate folders with their parents and sources. To do so, we need to play with relationships between models. Relationships can be declared using belongsTo and hasMany helper methods. Enriching models with relationships can be done using an Ember-like extend method:
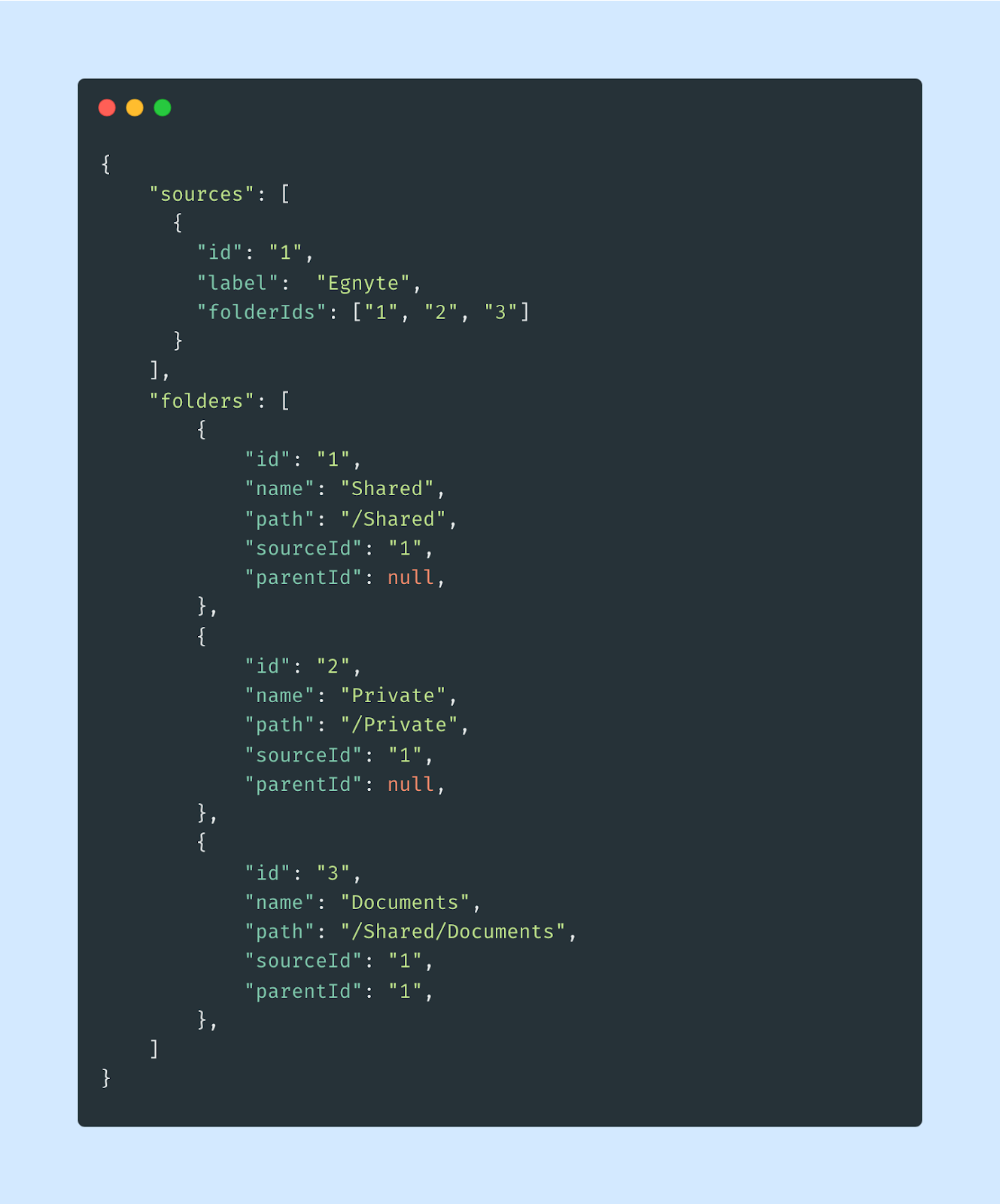
After this changes, the initial state can be populated in a way where some entities depend on each other:

The database state after applying the above snippet appears like this:
Scenarios
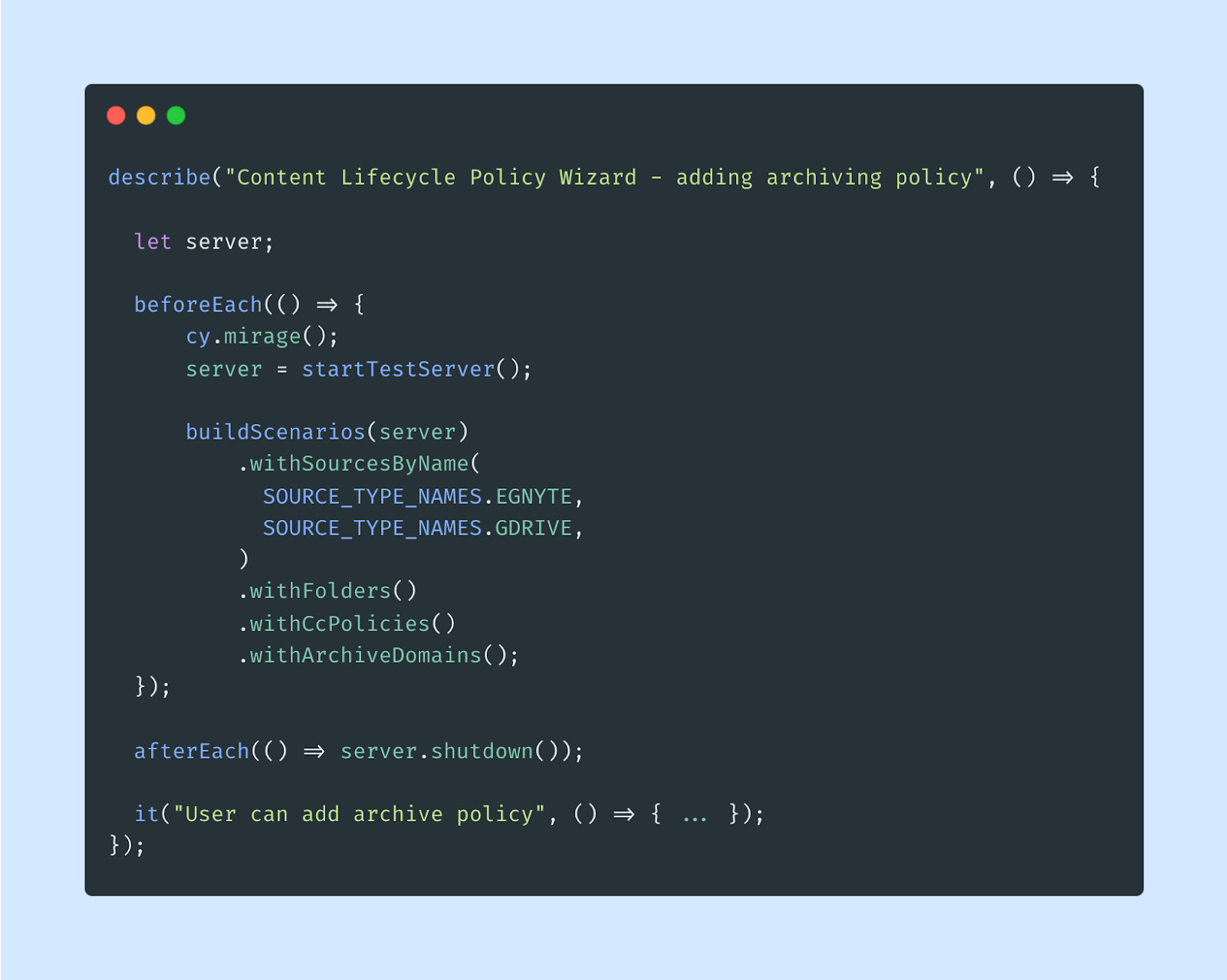
As you might have noticed, populating the database in the way described above can be a bit inefficient. To address such problems, we introduced a mechanism called scenarios for populating the database in a more declarative way.
Combining it with Mirage’s Factories gives a truly convenient way of creating entries depending on our needs. That is especially useful when writing tests, because we expect to have only a certain set of data in the database so we don’t affect performance. Here’s an example usage of scenarios in Cypress tests:
Serializers
Having the database populated with the expected data, we can deal with returning a well-formatted JSON inside the route handler for listing folders mentioned at the beginning of this section. By default, Mirage provides a special mechanism for formatting responses called Serializers.
Any Model or Collection returned from a route handler will pass through the serializer layer. The library implements a couple of built-in serializers like RestSerializer, JSONAPISerializer, or ActiveModelSerializer.
There is also an option to write a custom serializer that could be applied to a specific model.
Unfortunately, no built-in serializers were applicable for our internal API. What's more, defining serializers at the level of individual models was also insufficient since the shape suitable for models can vary depending on the specific route handler.
That was the first time when Mirage’s API appeared to be insufficient for us. To mitigate that issue, we decided to abandon the use of serializers.
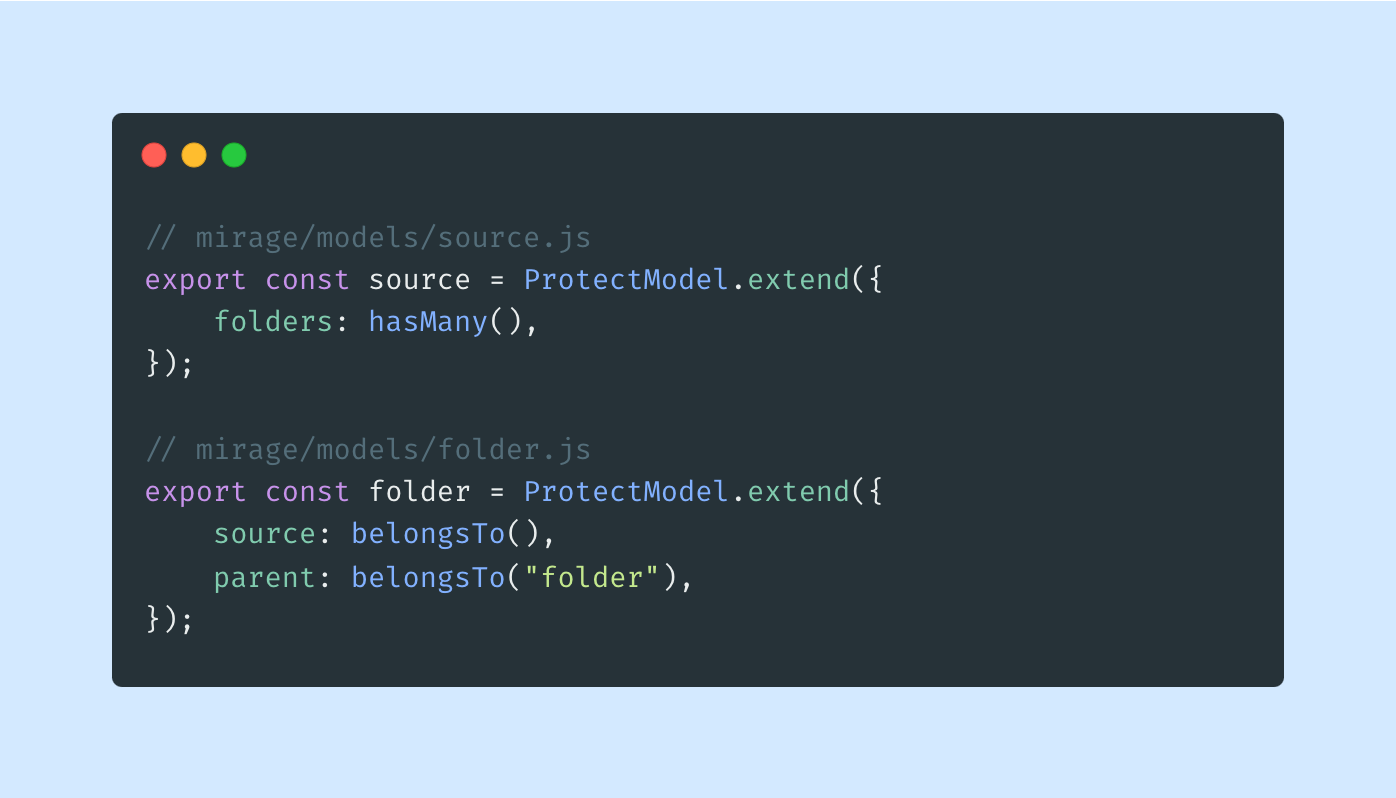
Instead, we created a custom class for defining models called ProtectModel. In essence, it is an extension of a regular Model class enriched with a few helper methods, which simplifies the way of creating any response by leveraging ORM and Builder pattern.
To utilize it inside route handlers, first we need to replace the Model class with ProtectModel in the models declaration:
After that, we can update the route handler implementation to use the schema object for accessing the database and models alongside with the request object, which contains relevant information about the concerned request:
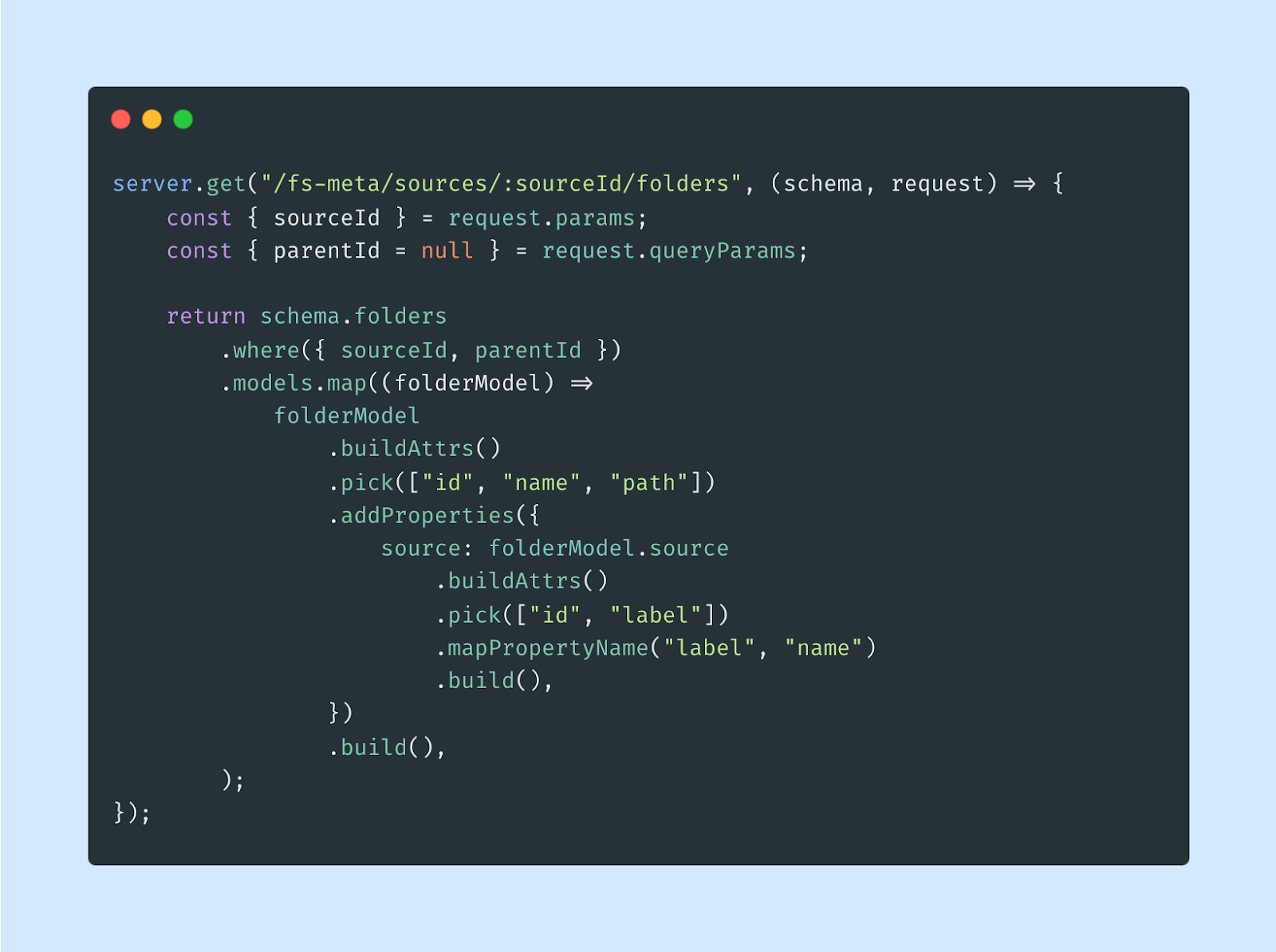
The above route handler is able to successfully return a dynamic response for an intercepted request, depending on passed sourceId and parentId.
Performance
Performance can be a big pain point in large-scale projects, and this one wasn't different. The problem arose when the amount of data began to be very large—like thousands of folders. As we mentioned at the beginning of this section, the Mirage server, by default, works entirely on the browser side. It introduced performance issues for the browser thread, which now had to deal with both the UI work and the calculation of responses for individual requests.
To mitigate that issue, the Mirage server was extracted to the worker thread. In essence, two Mirage servers are working simultaneously in this setup. The first one is responsible for intercepting requests from the browser and passing them to the second one, which runs on the worker thread dealing with heavy data-driven calculations. A single request flow can be described using this diagram:
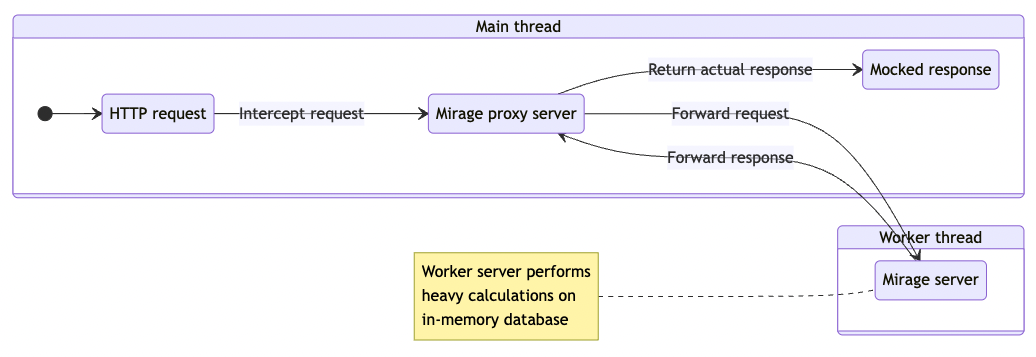
With this approach, the server no longer affects the performance of the browser thread. Even if a request requires a large amount of computation, the browser will simply wait a while longer to resolve the request, showing some spinner, without any damage to user experience.
Summary
This has been a brief description of how we address API mocking problems at Egnyte Secure & Govern. Thanks to the great work of the entire frontend team, we managed to create over 200 API route handlers on the basis of 60 models, which successfully cover all of the interactions with the real backend.
We achieved our goal—the same setup is being reused for many use cases. There is also one more important advantage of this solution—frontend developers are now obliged to better understand the dependencies between elements of our system, which leads to better cooperation with backend teams.






