
How Egnyte Achieves MySQL High Availability
At Egnyte we store, analyze, organize, and secure billions of files and petabytes of data from millions of users. On average, we observe more than a million API requests per minute. These API requests are a mix of metadata operations and analytical queries. As we scale, we have to address challenges associated with balancing throughput for individual users and delivering an exceptional quality of service.
We run several clusters of MySQL instances storing billions of metadata records. This is information about files, versions, folders, their relationships, and a rich set of extended metadata supplied explicitly by the user and derived from content analysis (named entities, applicable policies, and the like). We are a multi-tenant SaaS application and serve thousands of businesses storing hundreds of million items. MySQL is, therefore, a critical component in our stack and, given the scale at which Egnyte operates, we receive a very high number of queries per second (QPS)—hitting around 250,000 QPS on some clusters during peak hours:
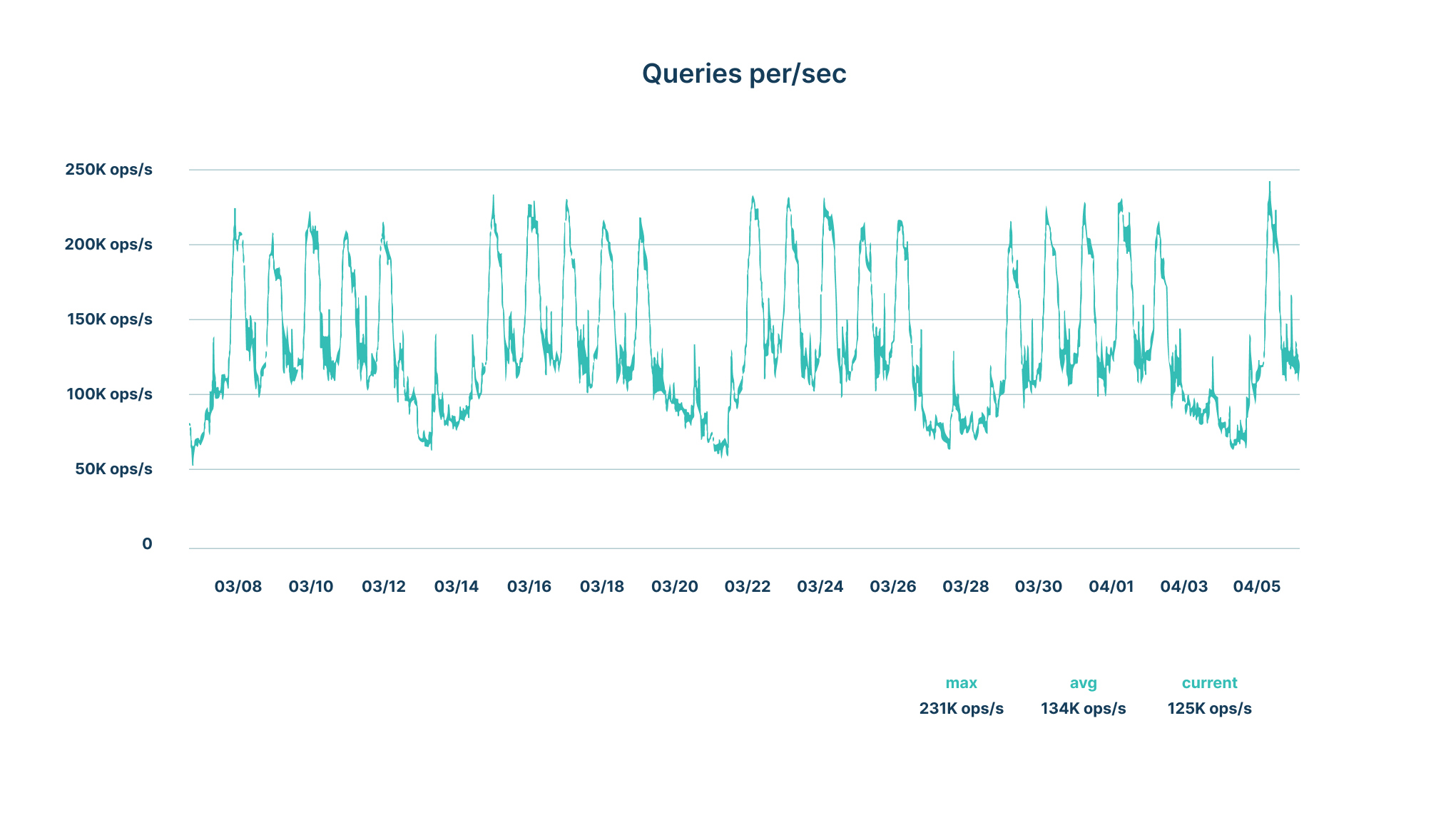
Based on the above stats it’s very important for us to ensure that our databases are highly available, performant, and scalable. In this blog, we'll discuss how Egnyte developed a cloud-based architecture that is resilient enough to meet customers' needs for 24/7 access to their most critical data.
High Availability Setup
Before implementing the setup described below, we used a mix of Master-Master and Master-Replica replication. To handle the failover, we were using a VIP (Virtual IP address) with the servers set up as active-passive, sending a few read-only queries to the secondary master (or replica). With this setup, we achieved semi-automatic failover that required manual intervention to ensure the new master was in sync.
As Egnyte began to use more public cloud resources, VIPs became a big issue since most cloud providers don’t support VIP. Additionally, there was a need to handle providers’ zonal and regional outages while dealing with potential network partitioning issues.
To achieve the goals of reliable detection, region-tolerant failovers, a reasonable failover time, and a reliable failover solution, we zeroed in on using Orchestrator, Consul, and ProxySQL.
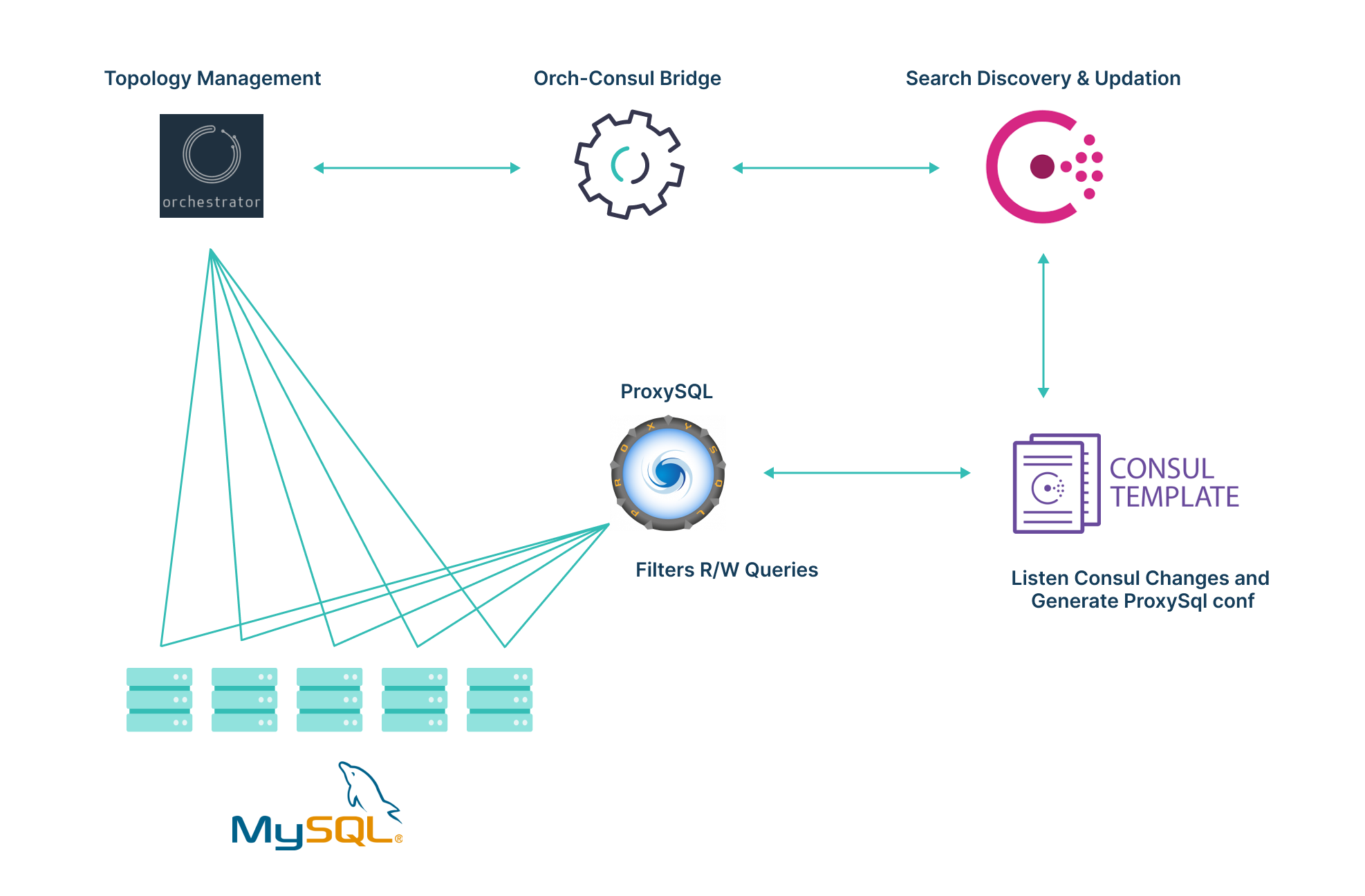
In this setup:
- Orchestrator monitors MySQL nodes.
- The Orch-Consul bridge service polls the Orchestrator and updates topology information in Consul KV.
- The Consul template listens to KV changes and updates the ProxySQL configuration.
- Clients connect to databases via ProxySQL.
We also gained insights from this blog from GitHub about how it uses Orchestrator.
This setup helps us because it:
- Provides an alternative to VIP
- Performs automatic failovers
- Supports zonal failovers
- Adds pre- and post-validation hooks before and after a failover to enforce integrity checks
Components
Here is a closer look at the components in our HA architecture and how we use them.
Orchestrator is an open source MySQL replication management and high availability solution.
With Orchestrator, we use a minimum of three-node clusters to handle failure of a single node. We made sure that all three nodes are deployed in three different zones so we can maintain quorum when one zone is down.
Consul is an open source service discovery, service mesh, and configuration management solution.
We already had a fully functional, highly available, and zone-aware cluster that we use for other highly available components in our stack. We installed Consul clients on the Orchestrator and ProxySQL nodes.
Orchestrator Consul Bridge is our custom-built service that communicates with the Orchestrator leader and updates the topology state in Consul KV. We wrote this service instead of using Orchestrator’s built-in KV support because we:
- Wanted replica health information for automatic replica failovers
- Needed more control on adding the failed nodes back into the pool
- Needed a co-master(aka Multi-Master) support to handle database migrations across regions
The service:
- Polls the Orchestrator at defined intervals
- Uses the Orchestrator API to get topology state
- Checks for differences from the current Consul state, and updates the changes idempotently to Consul KV
The service also has monitors to help alert for node failovers and connectivity issues between Orchestrator and Consul.
ProxySQL is an open source high-performance, high-availability, database protocol-aware proxy for MySQL. We chose ProxySQL to serve client requests because we found it to give good results in our latency benchmarking tests.
Some advantages of ProxySQL are:
- It is an application layer proxy
- Requires zero-downtime for changes
- Supports advanced Query Rules
- Has failure detection features
We are using two ProxySQL nodes that run independently. To provide HA for ProxySQL nodes we use a Layer 4 load balancer such as Internal TCP/UDP Load Balancing in an active-passive mode. This setup can handle one node failure. Clients communicate with ProxySQL nodes for read/write operations via the load balancer.
Consul Template was installed in the ProxySQL nodes. Consul Template listens to Consul KV changes and update the ProxySQL configuration based on the Orchestrator topology.
HAProxy fronts a three-node Orchestrator cluster in our setup. HAProxy is used to route all API traffic to the leader and to access the Orchestrator UI. It's also used by the monitoring system to ensure we always have the leader node up and running.
Failover process
Now that we’ve described the overall HA architecture and its components, let’s take a closer look at how it works, including the failover process and how we test and monitor to validate the setup.
First, the flowchart and corresponding steps below outline how we handle failovers.
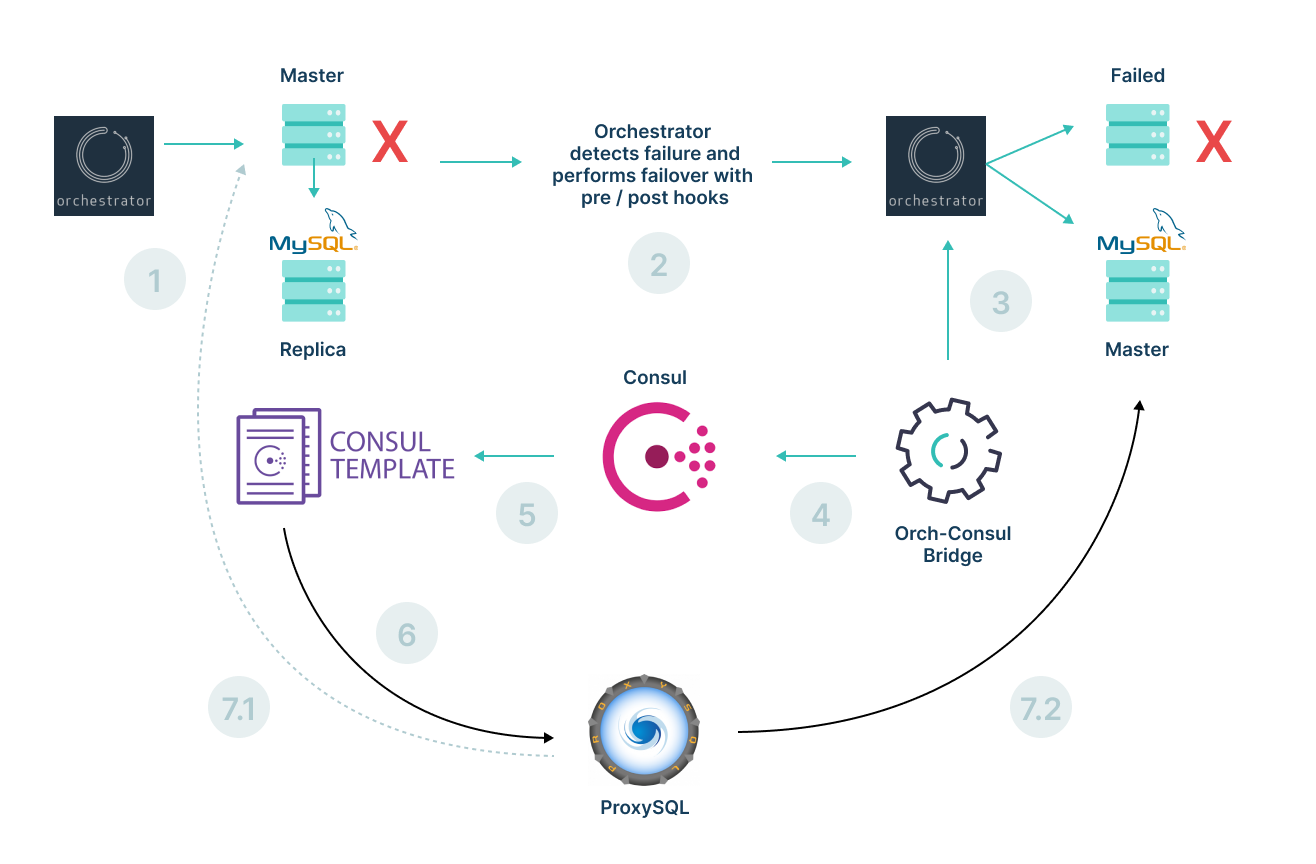
- Orchestrator monitors the health of MySQL servers.
- If it detects any failures, it starts the failover process for the failed node. It executes the pre-hook script, which does the failover validations as described in the failover validation section below. The replica is then promoted to master.
- Orchestrator Consul Bridge service monitors the state of Orchestrator.
- Orchestrator Consul Bridge service updates the latest Orchestrator state in Consul KV:
- The state of the failed node is marked as “Maintenance” in Consul KV.
- Orchestrator Bridge service skips subsequent updates to the Orchestrator state for nodes marked as “Maintenance” in Consul KV. This protects the MySQL node from being added in rotation without verification post-revival.
- Consul Template listens for changes to Consul KV.
- Consul Template updates ProxySQL configuration to reflect the latest Orchestrator state.
- State update in ProxySQL configuration:
- The old master node is removed from ProxySQL.
- The newly promoted master is added to the rotation and read/write traffic is routed to the new master.
- A pager alert is sent to the Operations team to run their due diligence checks. After confirming that the database is healthy, they remove the network tags and “Maintenance” state from Consul to add it back to the pool.
Failover validations
- We use Orchestrator’s Pre- and Post-hooks to do all validations.
- Pre-hook does many checks like replica lags and any errant transaction in the cluster. If there is an errant transaction in the cluster, we will not allow the failover because it may cause data inconsistency.
- In Post-hook we do verification checks and, finally, add the new master in write mode(read_only=OFF).
Handling Network Partitions
To test network partitioning tests, we isolated one zone from the network. For a short period during this network partitioned state, the old master received some writes until the active ProxySQL node had its configuration updated by the Consul Template. This happens because the traffic is now switched to the active ProxySQL node by the internal load balancer and the active ProxySQL node has an outdated configuration since it did not receive any updates during the network partitioning.
This was particularly relevant to errant transactions where the master failover happened to be in the same zone as the active ProxySQL node. In this scenario, when the network was restored the failed node came back, it still received some writes despite no longer being the master.
To prevent this issue, we blocked all active MySQL traffic on the failed host via network tags in the Orchestrator pre-failover script. This tag is removed by our DBAs after due diligence in the recovery steps using the provided CLI commands to add the node back in the rotation.
Testing
We test for:
- Master failover
- replica failover
- Zone failover
- Network partitioning failover(Split Brain testing)
In each case, we checked for data consistency post-failover.
Monitoring
We have monitoring in place for:
- Liveness check for all components
- Connectivity errors
- Errant transactions and data inconsistency
- Alerts for node failovers
- Detailed MySQL stats.
Performance Stats
We tested latency with respect to VIP, HAProxy, and ProxySQL, and found ProxySQL provided better performance than our existing on-premises solutions. We used the sysbench testing tool with multiple threads (16/32).
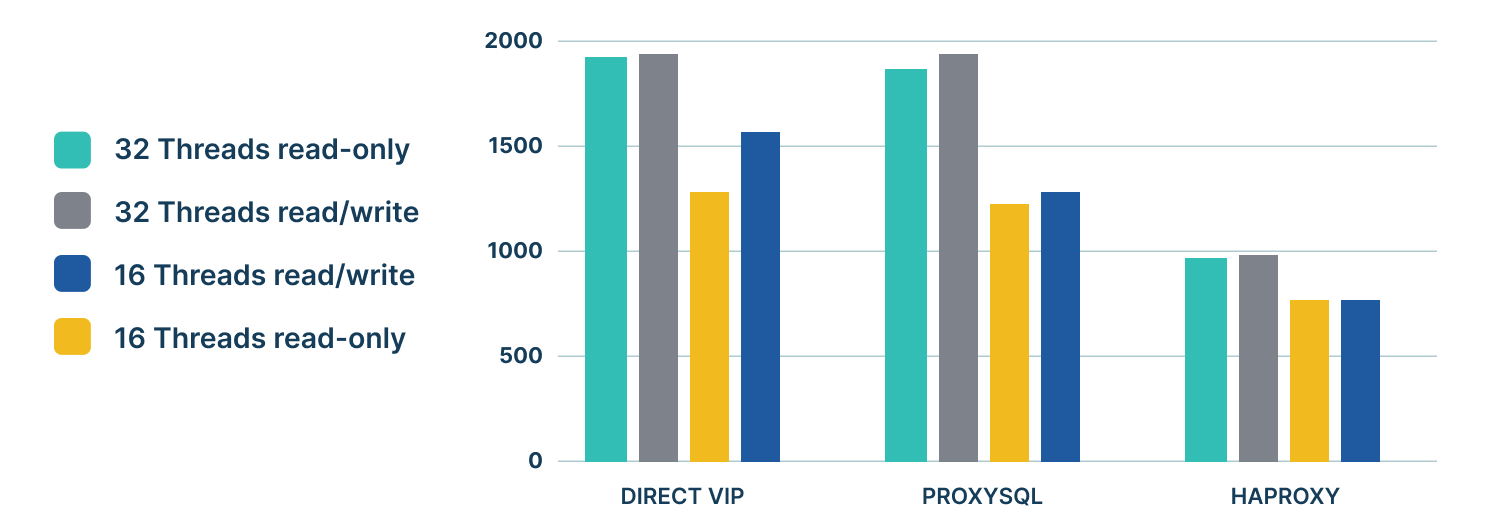
We did some synthetic benchmarking and found that HAProxy showed a nearly 40% drop in TPS and ProxySQL had around 5% to 10% drops in TPS compared to VIP.
Process Analysis
With this setup, we are able to achieve MySQL high availability with multi-zonal automatic failover support and quick recovery leading to minimum business interruptions. Of course, with any system, there are benefits and drawbacks. Here is our final takeaway regarding the pros and cons.
Pros
With this solution, we are able to achieve the following:
- Handle MySQL node failures automatically
- Support zone failover/network partition
- Make sure data is consistent before the failover to the second node
- ProxySQL and Orchestrator are closely coupled, which means whatever the state you see in Orchestrator, the same is reflected in ProxySQL
- All components in the solution are highly available leading to minimum interruption
Cons
With this solution, we have various moving components so we need to closely monitor for anomalies:
- MySQL HA depends on multiple moving components as all components are closely coupled so if anything happens, we need to depend on our monitoring system.
Ultimately, the pros outweigh the cons for our purposes. And to address the shortcomings, we built a strong monitoring system to ensure that if anything does go wrong, our system can detect it and alert the team.
If you're interested in solving hard problems at scale, we'd love to hear from you. Check out our careers page to learn more.
Editor's note: Ankit Kumar and Narendra Patel contributed to this project.






