MySQL at Egnyte
At Egnyte we recently got rid of NOSQL databases allowing us to get more predictable performance and the move is scaling beautifully. The move has significantly reduced downtimes and increased customer satisfaction, all across 20+ Mysql servers storing billions of rows.In this blog we’ll look at the three different classes of Mysql servers.
- Vertically sharded servers
- Horizontally sharded servers
- Data warehouse servers
We’ve found Sharding to be a double edged sword. On the one hand it allows us to scale applications with increases in our customer base but on other hand it is very hard to implement and maintain schema changes across the board. We have decided to take a middle ground approach where for every feature, we decide the growth pattern and usage, and only heavily used features are put it in Horizontally sharded servers. Our first instinct was to put it in vertically sharded servers, and if a feature outgrows our expectation then we just migrate the vertically sharded server to horizontally sharded servers. To understand this better, let me take a deeper dive1. Vertically sharded servers: When I joined the company things were stored in a NOSQL dbs and we were trying to move away from it, as it was not scaling. We tried moving everything to Mysql in one project but it became a monster, so we started moving parts of applications out into production using Mysql. This boosted our confidence in Mysql as more features successfully went live using it. We started with smaller pieces that didn't have >10-20M rows but needed Mysql for its ACID properties. Anticipating the growth we decided to create one schema per functionality and avoided joins between two schemas, joining them in application if required. This way if one feature became hot and used Mysql a lot, we could easily split and move that schema to its own server. We use memcached heavily and try to avoid making calls to databases as much as possible.Pros of this approach:
- Easier to understand for developers
- Local development happens on one Mysql server and deployment happens in a different topology.
- We can keep on adding more slaves if the app is read intensive, and we keep upgrading the hardware to buy more time until we move the feature to horizontally sharded databases.
Cons:
- For bigger datasets that cant fit in one server, this will only buys some more time to move to Horizontal sharding.
2. Horizontal sharding : In this sharding approach we basically distribute the data across many Mysql servers. We use two types of horizontal sharding:
- Customer or user : We use this in our MDB (metadata database). When a customer registers, we assign him a shard and all his metadata lives on that Mysql shard. Joins are easy in this approach, but hotspots becomes an issue if two big customers lands on one shard randomly and we redistribute the shards to shed load.
- Hash on key: This is used in our EOS (Egnyte object store) database. In this approach we distribute the data for a customer across many shards, and each record is assigned its own shard. There’s rarely a need to redistribute shards here, but joins can be difficult, so we only use features that don't require any joins.
Pros:
- Highly scalable and easy to shed load by adding more shards
Cons:
- Management overhead of multiple Mysql hosts and shards is difficult, though we have automated most of the processes.
- Applications become more complex so we recommend proper encapsulation of sharding logic so its present only in some key infrastructure layers.
Lets take a deep dive into both Horizontal sharding approaches used by us.Sharding by Customer or user : In our metadata db for files/folders we assign a shard to a customer on registration. We do this because most of our metadata queries require joins and we could not find an easy way to spread this across multiple servers in the allotted time. We find the eight least used shards and randomly pick one of them and assign the customer to it. We store the customer to shard mapping in a global db (aka dns or pod metadata db) and this is a highly cacheable data and we use memcache for it. Each incoming request looks up the shard ID by customer and looks up a connection pool out of a pool of connections, then executes the request.We divide our servers into pods so we can do rolling updates when any non-backward compatible changes are introduced. Several pods can live on the same Mysql host (typically in QA/UAT environments) and in production we are doing one pod per Mysql host right now. Later, we can easily add more Mysql hosts to that pod if the pod outgrows one Mysql host.
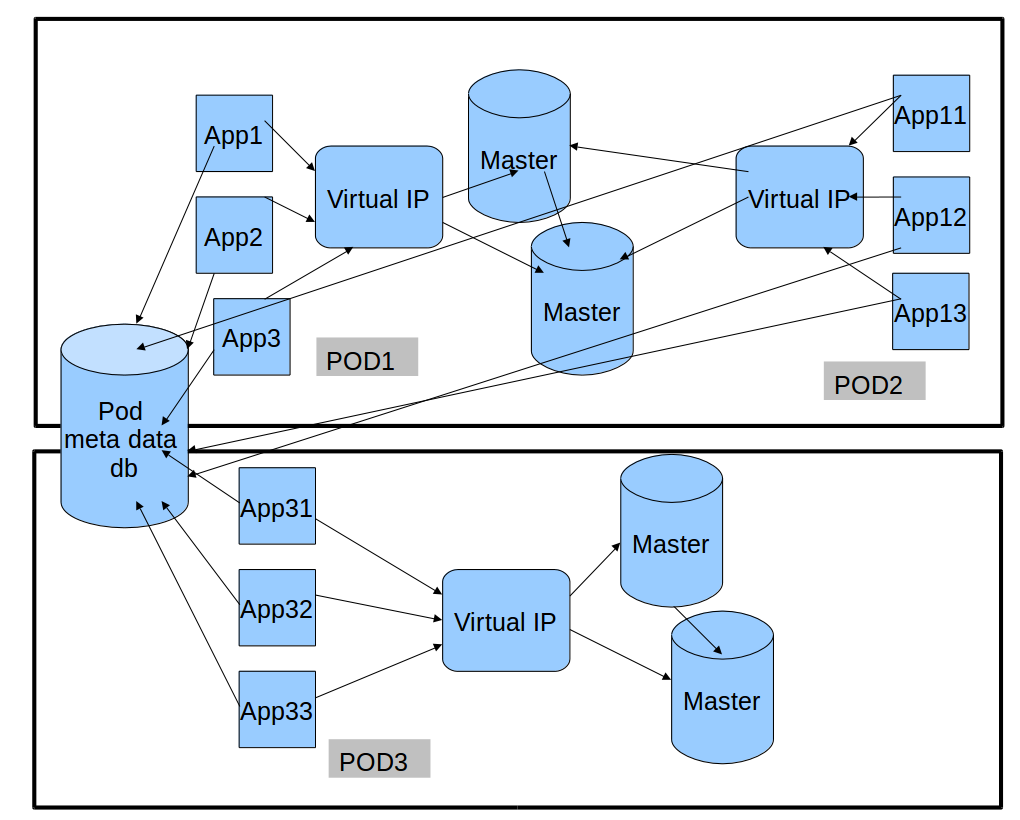
We have logical shards that are mapped to physical shards, and physical shards are mapped to a msyql host. All this information lives in pod metadata db. A typyical lookup looks like:
- Customer acme lives on logical shard 64. logical shard 64 lives on physical shard 5
- Physical shard 5 lives on host1 schema2
- Host1 belongs to Pod P1
The main reasons to come up with POD architecture were:
- Failure of a pod doesn't cause the entire DC to go down.
- We can update one pod and observe it for a week before pushing the release to all pods.
- We can have different capacity for different pods (Enterprise customers vs trial customers).
- We can add more pods or more Mysql hosts to one pod if it has a capacity problem in one component.
Ideally you want to make it as homogeneous as possible but let’s say for some reason in one pod people are doing more add/delete files than just adds, and delete causes index fragmentation, you can do aggressive index defrag on that one pod.Sharding by hash on key: In our highly scalable Egnyte object store database we use the other approach to sharding, where each object is assigned a shard ID based on least used shard and the shard ID is embedded in the Object key itself. We could spread one customer’s data onto multiple physical Mysql hosts because all queries are by object-id and do not require any joins. We maintain a logical shard to physical shard mapping in case we need to move the shard to some other host or redistribute it. Whenever an object needs to be looked up, we parse the object-id and get the logical shard id, from this we lookup the physical shard id and get a connection pool and do the query there. This approach does not have any hotspot issues and shedding load is very easy as we just add more shards on new physical hosts and immediately all new data would start going to empty shards. To scale reads on existing shards we can easily add more slaves and scale this.This should provide some insight into our thought processes on the nosql Mysql issue.ObjectId = 32.XXXXXXX maps to logical shard 32.logical shard 32 lives on physical shard 4physical shard 4 lives on host2, schema5