How we used cheaper disk space to scale snapshot performance
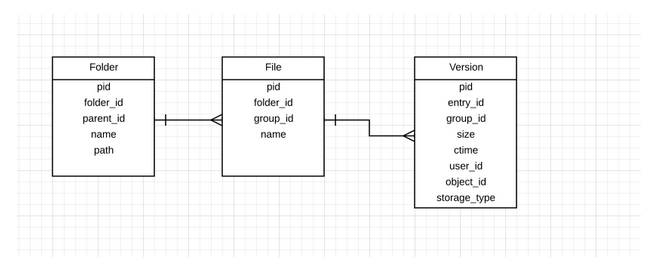
Memory and CPU on MySQL servers are costly compared to disk space. As our customers are adding more and more files to their Egnyte accounts, the metadata stored on Egnyte’s MySQL servers is increasing, as well as CPU and I/O loads. We needed to address this issue to decrease the loads, reduce maintenance downtime windows and improve sync reliability for our customers.As a first step to resolving this issue on a hot MySQL server, we originally split the server into two and created new shards into both of them. The problem with this approach was that it required downtime, and the numbers were not just adding up as other types of MySQL servers were storing more rows than metadata MySQL servers.We analyzed the top queries, which were both CPU and I/O intensive, and found that we had stored our data in a normalized form to save disk space. If we could switch this to a denormalize from, we would use more disk space but could optimize and reduce memory, I/O and CPU consumption. We would also be able to pack more rows on one MySQL server and continue to serve the same queries without the downtime required to split the servers.We store metadata for billions of files in MySQL shards with each shard having a folder, file and version table. This data was previously stored in a normalized fashion, and the schema used to look something like this:
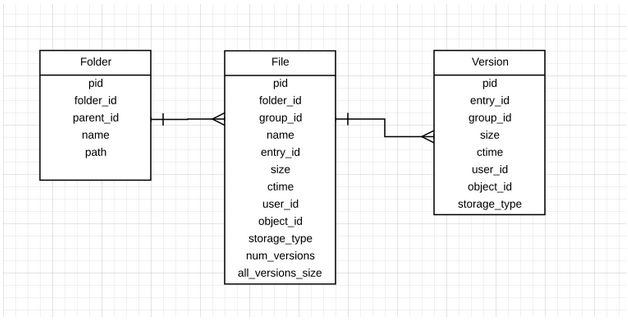
One of the constant scaling issues is: how do you generate the latest snapshot of the cloud file system and send it to the client to start an initial sync and then switch to event-based sync. If a certain file has 10 versions, then for the latest snapshot, we only need the latest version. When we moved to MySQL two years ago, we started with a join query in MySQL with a correlated subquery to filter the latest file. This approach worked for customers with <5M files, but this was causing I/O and CPU issues on the MySQL server.We moved to the new approach of joining the folder, file, and version table and then sorting the output on Unix by using a Python script to filter the latest version. It was faster than correlated queries, but it too buckled under pressure when we hit customers with 25M+ files. This was causing Memory and I/O issues in some of the hot MySQL servers. For larger customers, we had to constantly defrag the tables in the background to ensure the join dataset would fit in the MySQL cache. This approach wasn’t going to scale as more and more customers upload large numbers of document versions. The more versions they upload, the slower the snapshot query becomes due to joins. We thought, why not use cheaper disk space on MySQL boxes and avoid the join by denormalizing the latest version on the file table.The new schema looks somewhat like this:
To generate the latest snapshot, we now join the folder and file tables. We graph slow queries from all MySQL databases to a centralized dashboard. In the below screenshot, the second query is a normalized query and the third query is a denormalized query. For an average-sized customer, the time of the snapshot query has reduced three times (486 sec to 159 sec); also, the number of rows examined in MySQL and rows sent to the snapshot processor has reduced by half.

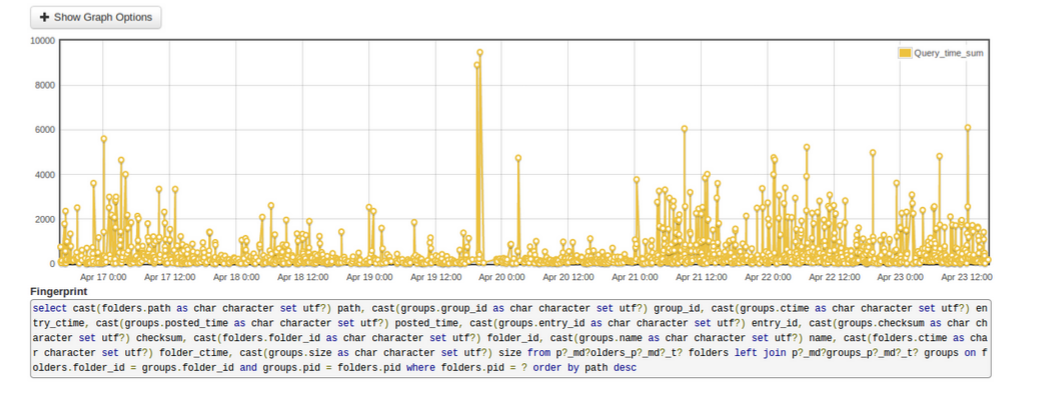
This frees up MySQL time to process other queries. No Unix sort is required, and that reduces snapshot time for customers with large numbers of files.Here is the normalized query graph:
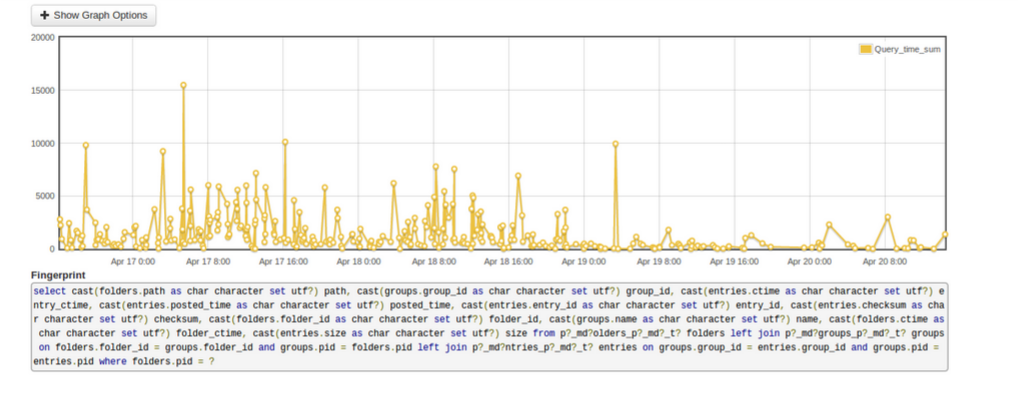
Here is the denormalized query graph:
Denormalizing billions of rows has unique challenges, and we needed to do it without impacting customers. We spread billions of rows across 50+ master MySQL servers.To do performance testing, we took an average database with some customers having 30M+ rows and imported it in a test environment and migrated it.30M+ versions snapshot times before denormalization = 1.5 hours30M+ versions snapshot times from denormalized tables = 6.5 minutes constantAs we were doubling the data, we had to optimize the database tables after denormalization or we would run into IO issues.For launching the new approach, we started with feature flags and added two flags: latest_entry_migrated and latest_entry_active field on each customer object. Then we wrote code for that on the basis that latest_entry_active flag would execute normalized or denormalized queries. Once the code was live in all services, we began migration for a few workgroups to test for any bugs. After a week or so, we started migrating 10K+ customers every weekend, and in a month or so, we had all databases upgraded with denormalized rows. The size of the database has grown and full backup times on the MySQL servers have increased, and in many databases, the snapshot queries have disappeared from slow query logs. We still split MySQL servers to relieve occasional load issues, and the rate at which we split the server has gone down and this has reduced maintenance downtime windows and improved sync reliability.Kalpesh Patel is an Architect spending most of his time on implementing, scaling and monitoring various cloud file server products at Egnyte.