
Data Durability at Egnyte: Understanding Our Cloud Object Store
In today's digital era, data is the lifeblood of any business, and at Egnyte, we're acutely aware of the need for data availability and durability. We have designed our specialized cloud file system, a harmonious blend of a file system and an object store, to meet these indispensable requirements.
While we at Egnyte don't explicitly label ourselves as a data storage company, there's no escaping that we're in the business of persisting data—lots of it, into billions of files. Our customers' requirements to safeguard, retrieve, and distribute files emphasize that data persistence is a domain we need to be adept at.
Many people undervalue the intricate process of persisting and securing billions of files, just like the automatic garbage collection in programming languages—vital, yet rarely noticed. The task of persisting data at Egnyte, now executed with impressive consistency and frequency, reflects our years of hard work and optimization.
Here's how it works.
Cloud File System At Egnyte
At the heart of Egnyte's operations lies our cloud file system, divided into two major components:
1. Object Store: The Object Store is the backbone of our operation, handling all tasks related to the byte-level details of files. This includes persistence, replication, durability, and availability, performing much like a RAID controller.
2. File System: On the other hand, the File System is responsible for all metadata-based operations that don't involve file contents. This system manages files (focusing on file identifiers, not contents), folders, and related operations.
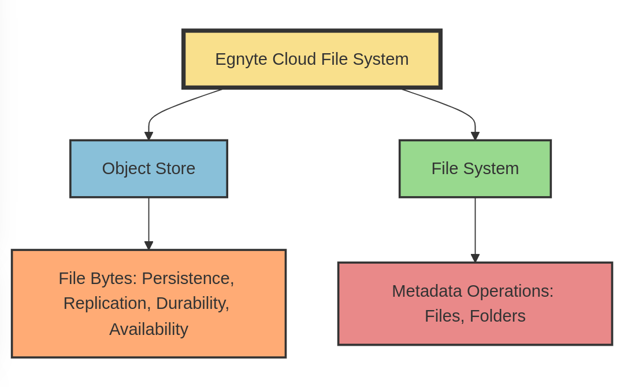
Such a design allows us to design and focus on each part independently. From the object store perspective, it will enable us to focus on storage-availability and durability-specific design and scale it independently. From a security perspective, it allows us to establish appropriate policies and measures to access and safeguard data at rest.
How Data is Stored in Egnyte Object Store
When a user uploads a file to the file system, they essentially upload an object to the object store. A file identifier is created at the file system level and is linked with an object identifier in the object store. This process ensures that each file is accurately tracked and stored.
An object can be saved as a single entity or split into several smaller parts within the object store. Throughout the rest of the document, the term "object" refers to both formats.
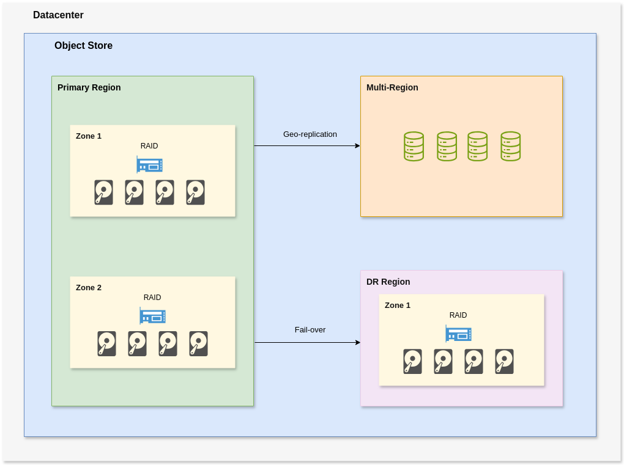
From the object store perspective, it's essential to emphasize the importance of storing multiple copies of each object. This strategy is crucial for data redundancy and ensuring data availability and integrity in various scenarios.
In the event of machine failures, RAID (Redundant Array of Independent Disks) technology stores copies of data across multiple disks. This method provides a safety net, ensuring that data is not lost if one disk fails.
Multiple copies of each object are stored in different zones to safeguard against multi-regional failures. This geographical distribution of data ensures that even if a whole zone experiences an outage, the data remains accessible from another zone.
Lastly, multi-regional copies are maintained to cover disaster recovery (DR) scenarios. This approach ensures that even when a catastrophic disaster affects an entire region, the data is still safely stored and accessible in another region.
In essence, uploading a file to the file system is not just about storing data but also about implementing robust strategies to protect and ensure the availability of that data under various circumstances.
The Lifecycle of an Object
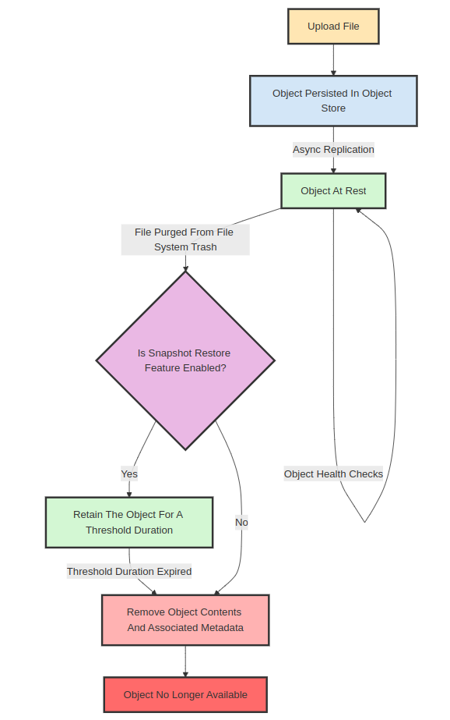
Each object uploaded to the object store is immutable and follows a cycle of creation, existence, and deletion.
Creation
The creation phase begins when a file is uploaded to the file system, resulting in an object being persisted in the object store. Each object has a replication policy associated with it to ensure its availability and durability. This policy defines how many copies of the object we need to create and where they need to be stored. As part of object upload, we persist it to a minimum of 2 storage locations (sometimes more) before marking the upload as complete. For each upload, we implement a checksum-based verification mechanism to ensure that the data received from the end user matches what we store in our storage locations. We also encrypt the data before persistence. The object store then asynchronously replicates the object to the appropriate storage locations according to the replication policy.
Existence
An object can exist in multiple geographically distributed locations to ensure that a copy of the object is always available. The object store periodically checks the object's health to ensure that it is present in appropriate storage locations per its replication policy. If not, the object store attempts replication again to satisfy the policy. These health evaluations encompass integrity assessments, consistency verifications, data sanitization, and automatic data fixing. Additionally, the object store verifies that the object is not corrupt, meaning the current checksum of the object has stayed the same since its creation.
Deletion
When a file is purged from system trash, the objects corresponding to it are also removed from the object store.
However, for customers who use Egnyte’s Advanced Snapshot & Recovery feature, the object store keeps the object in a soft-deleted state for a certain threshold period, ranging from days to months. It allows users to recover files accidentally deleted or lost due to a ransomware attack within a specified time frame.
Customers can select and restore data from any available snapshot within this time frame by utilizing point-in-time snapshots of the file system. The restoration process for the customer is straightforward: they select a suitable snapshot, mount it, navigate through it, select the desired files or folders, and restore.
Once the threshold period has elapsed, the object store purges the object. This involves removing the file contents associated with the object identifier and flushing any metadata related to the object identifier.
Conclusion
Today, the seemingly effortless data storage process masks its past complexity and the challenges we navigated to refine it. Yet, this process of evolution and our expertise in data manipulation and management, as evidenced by patents US-11582198-B2 and US-9614912-B2, have led us to our current position of strength.
At Egnyte, we're committed to maintaining the highest data durability and availability standards. By leveraging advanced cloud storage techniques, we ensure that your data is always safe, secure, and accessible when you need it.





